
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

最終更新日:2023/01/31
こんにちは。エンジニアの小原です。
連載「現場にコミットする機械学習ノート」では、論文を詳しく読み解きながら、現場で使えるAI実装のヒントを記録していきたいと思います。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

前回の記事では、「YouTubeのコメントを復讐手法で分析」を扱いました。
今回は、韓国のHanbat National UniversityのD. Kwakらが2020年4月に発表した「画像に映る物体の奥行きを推定する」に関する論文を扱っていきます。
もくじ
1章 3次元情報の重要性
2章 サイクルGANとセグメンテーションから単一の画像に映る物体の深度を推測することに成功
2.1 研究目的:単一画像から奥行きを考える
2.2 研究手法:「サイクルGAN」を活用
2.3 研究結果:スマートフォンでも力を発揮!
■前回の記事:【vol.18】YouTubeのコメントを復讐手法で分析
1章 3次元情報の重要性
視覚情報に加えて奥行きや縮尺などの空間情報は、VRやAR(拡張現実)、自動運転などといった分野の発展に欠かせないものになってきました。
3次元情報を取得する方法は複数ありますが、その中の一つに2次元の画像から3次元情報を検出する手法があります。このような技術を用いれば複数のセンサーなどを用いて3次元情報の測定も不要なので、3次元情報を必要とする現場での導入時の負担は小さくなり、不動産における内見や建築などの分野で利用可能なのではないでしょか?
韓国のD. Kwakらは、サイクルGANとセグメンテーションを組み合わせて奥行き情報を推定することを試みました。
2章 サイクルGANとセグメンテーションから単一の画像に映る物体の深度を推測することに成功
まずはD. Kwakらの研究におけるミッション・手法・結果をまとめます。
|
✔️ミッション ✔️解決手法 ✔️結果 |
研究の詳細を以下で述べます。
2.1 研究目的:単一画像から奥行きを考える
最近では、機械学習を用いて単一画像から3次元情報を取得する研究が増えてきています。従来の深度推定手法では特殊な装置や複数の画像を必要とするため、コスト面、拡張性、小型化において課題がありましたが、単一画像から3次元情報を取得できれば、これらの課題が解決されます。
また奥行き情報の推定は、特に光流や点群のように他の情報を利用できないアプリケーションでは重要です。
よってD. KwakらはサイクルGANを用いて単一画像から深度を推定することに試みました。
2.2 研究手法:「サイクルGAN」を活用
D. Kwakらは、サイクルGANを用いて画像データをセグメンテーションと奥行きの2つの形態に変換し、奥行きの精度を向上させる手法を提案しました。
[データ]
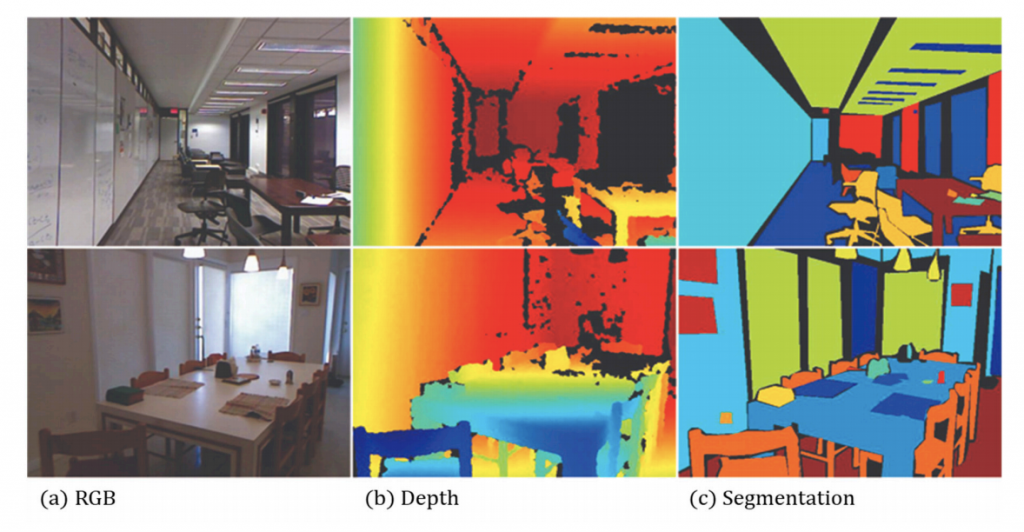
NYU Depth Dataset V2データセットを用いました。(約5000枚の学習画像)
このデータベースは、下図のように様々な屋内の動画シーケンスデータを提供しています。
さらにRGB画像の深度情報とセグメンテーション情報もまた含んでいます。

[アルゴリズム]
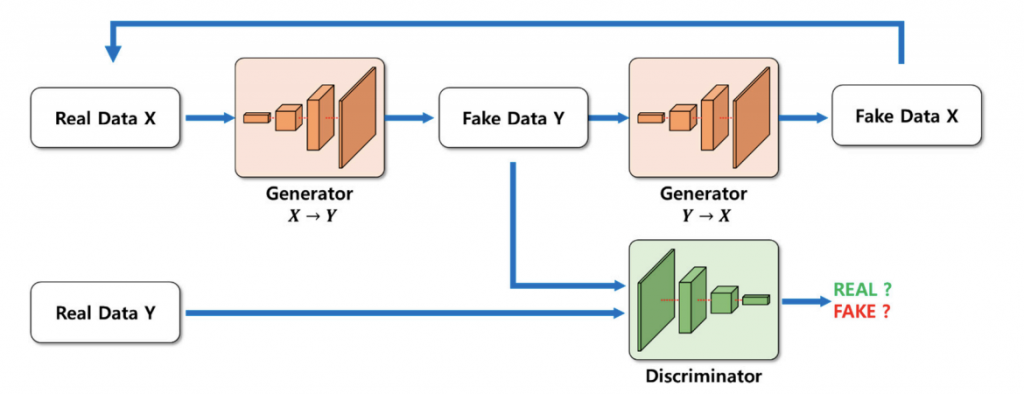
D. Kwakらは深さ情報を正確に推定するためにサイクルGANを用いました。
その理由は以下の通りです。
・学習データ量が多いにもかかわらず、他のネットワークよりも高い解像度に対応しているから。
・ニューラルネットワークに入力されるRGB画像と出力画像の形状が維持されるから。
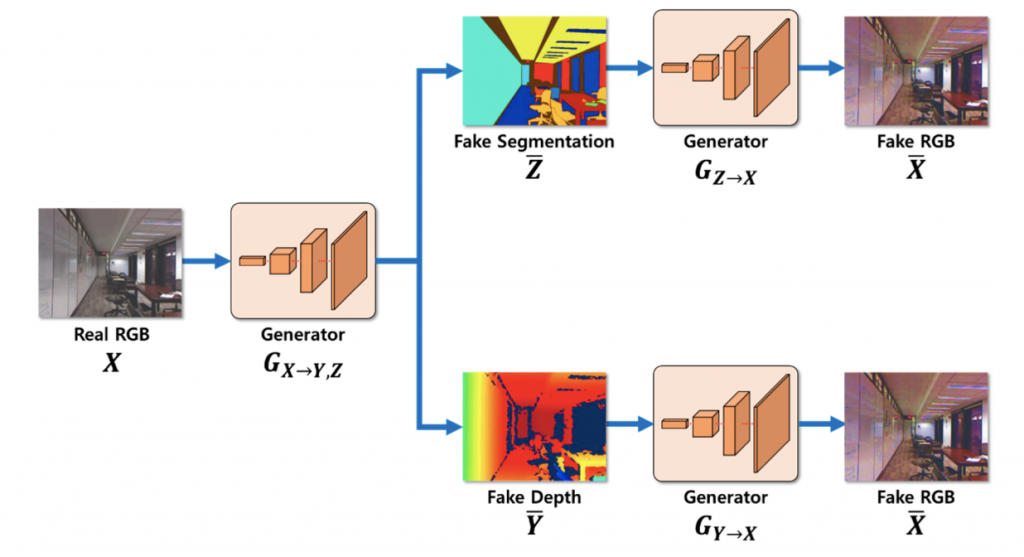
学習 1. RGB画像から深度、セグメンテーションを推定し、RGBに復元する。
RGBの入力画像Xに対して、生成器GX→Y,Zによりセグメンテーションと奥行き推定を行います。その後、生成器GX→Y,Zを用いて、推定された画像を再び復元します。
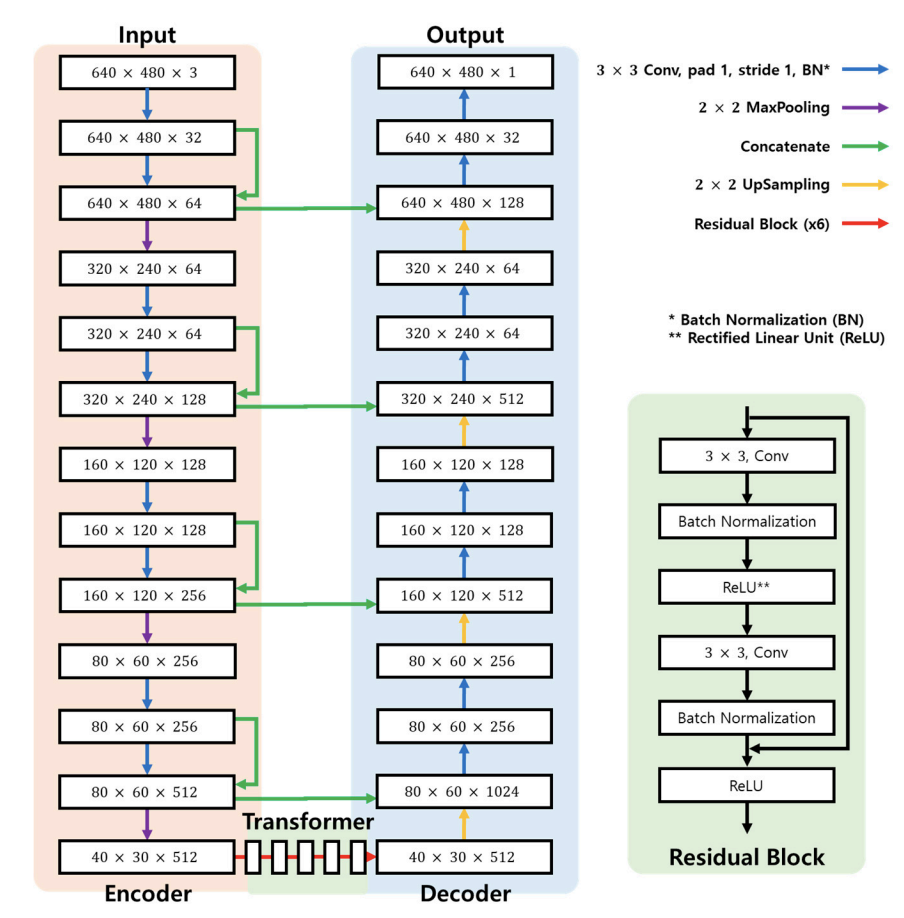
[生成器(Generator)の構造]
生成器のエンコーダは、入力画像の特徴量を抽出する。トランスは、エンコーダで生成された特徴量マップを、残差ブロックを用いて深度特徴量とセグメンテーション特徴量に変換します。最後のデコーダでは、深度とセグメンテーションの偽画像を作成します。
学習 2. 敵対的損失を計算する
深度推定画像とセグメンテーション推定画像と訓練データとを比較し、敵対的損失と識別器の識別確率を計算して生成器と判別器にフィードバックします。
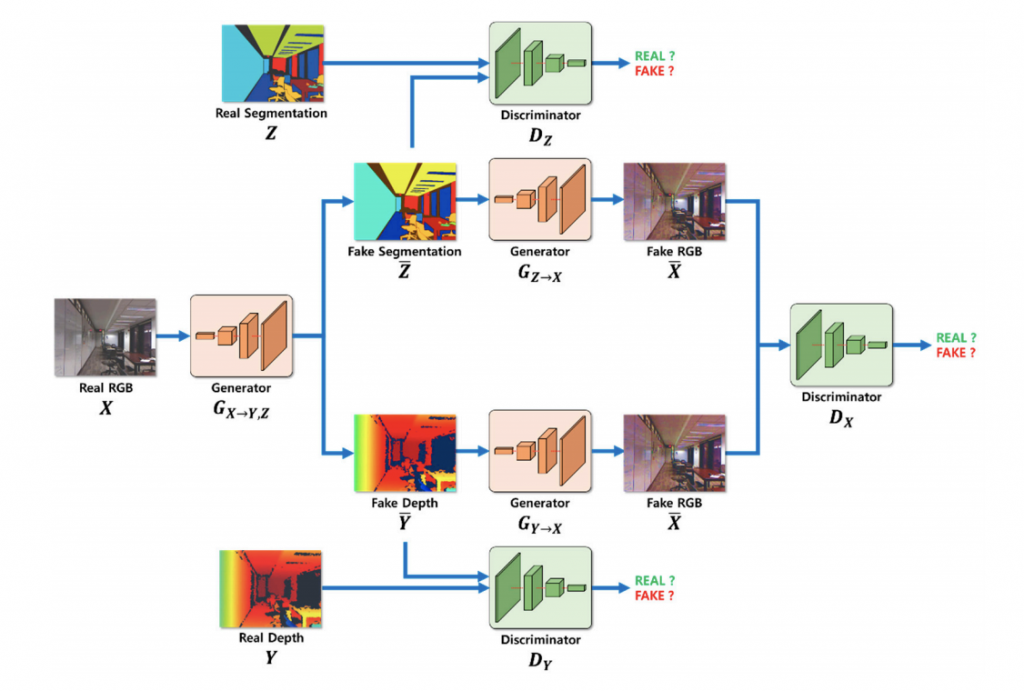
[識別器(Discriminator)の構造]
ネットワークは 6 つの畳み込み層を持ち、フィルタサイズは 3 × 3 です。 活性化関数には Tanh を使用しました。
識別器の入力は、訓練画像と生成器で生成された偽画像を連結したものです。
識別器の出力は、データインスタンスと実際の訓練データセットとの間の類似度を0から1の間の確率値として示し、生成された確率値は再び生成器にフィードバックされます。

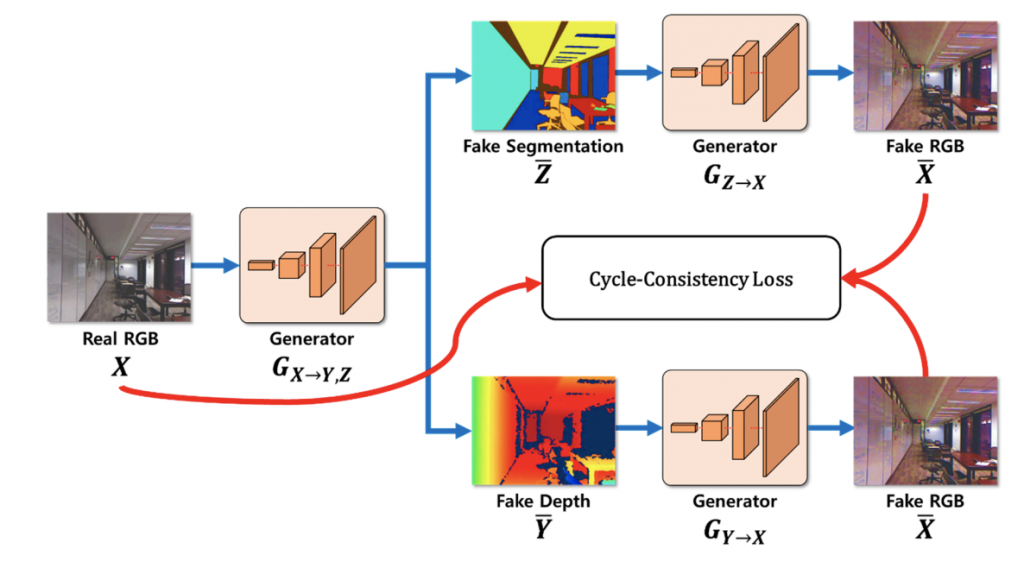
学習 3. 学習過程におけるサイクル整合性損失を計算する。
二つの生成器によって復元された2つのRGB画像と元のRGB画像とを比較してそれぞれの損失を加味することでサイクル整合性損失を計算します。
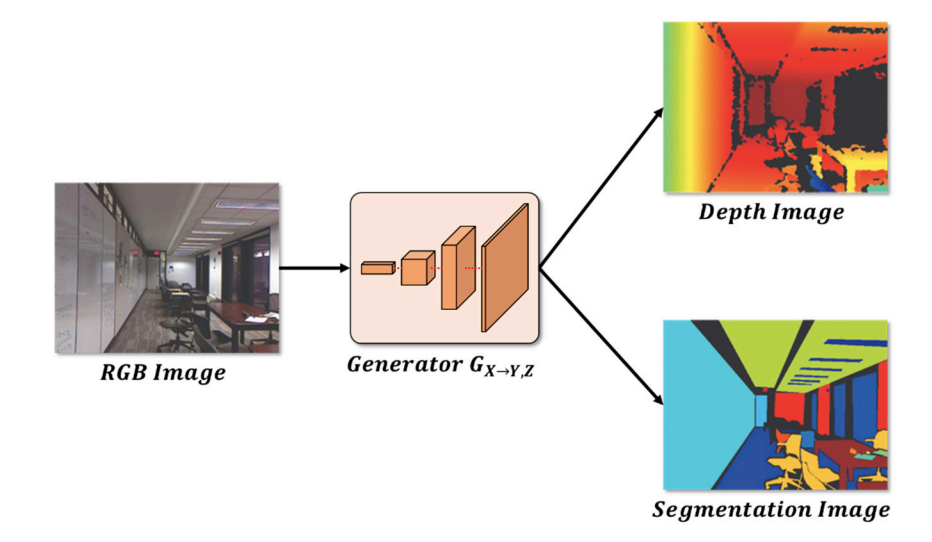
4. 推論
RGB画像を入力として、深度画像、セグメンテーション画像を生成します。
2.3 研究結果:スマートフォンでも力を発揮!
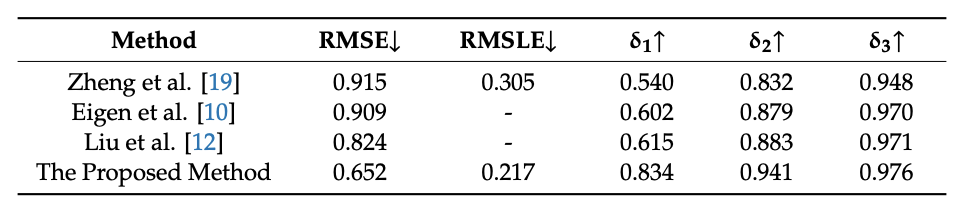
結果、提案手法は既存の手法に比べて性能が優れていることがわかりました。(δ1:0.834,δ2:0.941,δ3:0.976)
[NYU Depth Dataset V2における既存手法との比較結果]
RMSEの値は低いほど、δ1,δ2,δ3の値は高いほどより良い深度推定手法であることを示しています。したがって,提案手法は他の手法よりも優れた深度推定を示していることがわかり、提案手法はより効率的な手法であると考えられます。
[セグメンテーションを行わない場合と行う場合との比較結果]
セグメンテーションを除去した結果よりも、深さとセグメンテーションを組み合わせた場合の結果の方が優れていることがわかります。

[スマートフォンで撮影した場合の出力結果]
深度推定が正確に行われたことがわかります。

研究紹介は以上です。
XR時代が来る中で、このように2次元データから3次元データを抽出する技術にはこれからより注目が集まるのではないでしょうか?
今回は「画像に映る物体の奥行きを推定する」について解説しました。
【現場にコミットする機械学習ノート・バックナンバー】

【vol.1】ウェハーの欠陥の分類
【vol.2】うつ病の分類
【vol.3】RNNによる農地作物の分類 #農業DXシリーズ
【vol.4】CNNによる土地の分類 #農業DXシリーズ
【vol.5】土地分類の一般化 #農業DXシリーズ
【vol.6】エッジデバイスで動く異常検知システム
【vol.7】エッジAIで異常を早期警告」
【vol.8】監視カメラ映像から危険物を検出
【vol.9】冬の画像を夏の画像に変換するAI技術
【vol.10】フルHDのアイトラッキング
【vol.11】可視光データで洪水状況を把握
【vol.12】衛星データとGoogle Earthエンジンで洪水を把握
【vol.13】音響を深層学習で船舶の種類を分類
【vol.14】キャベツ苗の欠陥を識別
すべてのバックナンバーはこちら
この記事で取り扱った論文:D. Kwak and S. Lee,”A Novel Method for Estimating Monocular Depth Using Cycle GAN and Segmentation”,Sensors 2020, 20(9), 2567 DOI
※過去の全記事を閲覧されたい方はこちらからご登録よろしくお願いします!(会員登録は無料です。)
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。


























 PAGE TOP
PAGE TOP