
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

最終更新日:2022/12/05
嘘が蔓延するインターネットの海から、真実を見抜くことはできるか。
もくじ
課題:WEB上には嘘の情報が蔓延している
テーマ:嘘検知のための予測モデルを構築する
目的:嘘情報を自動検出したい
手法:4つの機械学習モデルで嘘情報の種類と手法を予測した
結果:種類はF1スコア 0.82、手法はF1スコア 0.66で予測できた
課題:WEB上には嘘の情報が蔓延している
Twitterでは誤解を招く表現や嘘を含む可能性のあるツイートに対して、ラベル付けを行う対策をとっている。実際、トランプ大統領の郵送投票に関する2つのツイートにもラベルが付与されており、誤解を招く可能性のある情報が含まれていたとされている。
一方で、トランプ大統領は、服用している薬についても誤った情報をツイートしたが、このツイートに関してはラベルが付与されなかった。嘘を自動検出する研究も数多くされているが、これまで嘘情報の種類と方法には注目されてこなかった。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

WEB上における嘘の情報を詳細に見抜くために、テクノロジーはどのように活用されているのだろうか。米国エネルギー省の国立研究所の1つであるパシフィック・ノースウェスト・ナショナル・ラボラトリーのSvitlana Volkovaら研究者の発表を紹介したい。
彼らは、ディープラーニングを使用して、嘘情報の種類と手法の予測を試みたのだった。
テーマ:嘘検知のための予測モデルを構築する
まずはSvitlanaらの研究におけるミッション・手法・結果をまとめた。
|
✔️ミッション ✔️解決手法 ✔️結果 |
ミッションから説明していく。
目的:嘘情報を自動検出したい


WEB上は、フェイクニュースや虚偽を含むレビューなどの嘘の情報に溢れている。こうした欺瞞的な情報を自動判別する研究はこれまで行われてきたが、多くは小さなコーパスに依存していた。
また、Twitterデータを用いて情報の信頼性やフェイクニュースの種類を予測する研究もあるものの、こうした嘘の情報の発信者の意図にまで踏み込んだ研究は少なかった。
手法:4つの機械学習モデルで嘘情報の種類と手法を予測した
Svitlanaらは、以下の3つを実施した。
- 嘘情報の種類と手法における言語的な認識を整理した
- 嘘情報の背後にある書き手の視点と手法を深く理解した
- 上記の知見を取り入れ、嘘検知のための予測モデルを構築した
嘘情報の種類
先行研究をもとに嘘情報を3種類に振り分けた。

- Hoax(でっちあげ)
- 読み手を故意にだますことを目的とした架空の情報
- Propaganda(プロパガンダ)
- 政治的・思想的・宗教的な目的のために特定の対象者に影響を与えようとする一方的なメッセージ
- Disinformation(偽情報)
- 意図的に読者を欺くために考案された誤った事実
欺瞞の方法
- Misleading(ミスリード)
- Falsification(改ざん)
これらの嘘情報の種類と手法、データセットを利用して、道徳的な基盤と意味合いを分析し、対比した。また、この知見を機械学習とディープラーニングによる予測モデルに組み込むことで、嘘情報の種類と手法を自動的に推測した。

使用するデータセットと予測モデル
- 嘘情報の要約:European Union’s East Strategic Communications Task Force in 2015 – 2016
- 偽のニュースページ
- 虚偽を含むツイート
予測には、scikit-learnに実装されたMaxEntropyとランダムフォレスト、kerasで実装されたLSTMとCNNベースのモデルの4つをそれぞれ使用している。
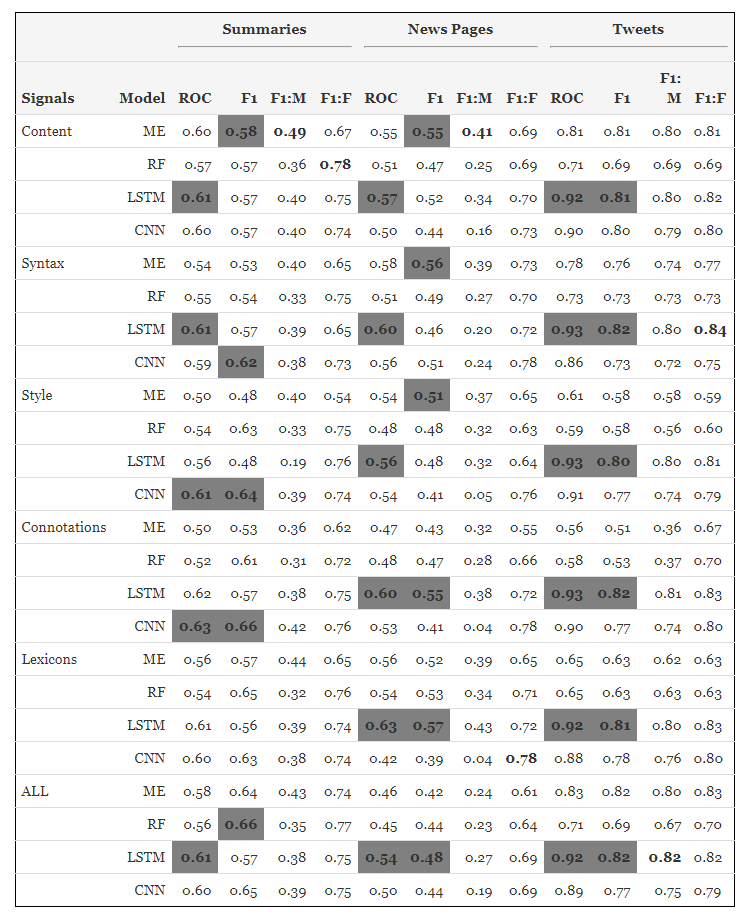
結果:種類はF1スコア0.82、手法はF1スコア0.66で予測できた
結果、嘘情報のタイプの予測ではLSTMの組み合わせが最も性能が高く、WEBページを対象とした場合F1スコアが0.82、ツイートを対象とした場合F1スコアが0.87となった。
嘘情報の手法の予測ではCNNの組み合わせが最も性能が高く、要約を対象とした場合F1スコアが0.66、ROCが0.63であった。
研究紹介は以上だ。
嘘を嘘と見抜けない人にはインターネットを使うには早いと言われているが、むしろ全ての嘘を的確に見抜ける人などほとんどいないだろう。また、近年のDeep Learningによって虚偽の文章や画像を生成することが容易になっている。こういった状況から、偽情報を自動検出する研究がさらに求められている。
「AI×ウェブ」のほかの記事もどうぞ
▶ 「危険すぎる」と話題のOpenAIの文書生成ツールを悪用してみたら・・・
▶ 「噂」のリツイートに踊らされないための技術が開発された
▶ AIがツイッター警察に!過激なツイートを機械学習で識別する
この記事で取り扱った論文:Volkova, Svitlana, and Jin Yea Jang. “Misleading or falsification: Inferring deceptive strategies and types in online news and social media.” Companion Proceedings of the The Web Conference 2018. 2018 - DOI
※過去の全記事を閲覧されたい方はこちらからご登録よろしくお願いします!(会員登録は無料です。)

■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。



























 PAGE TOP
PAGE TOP