
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

LLMをはじめとしたAI技術は、日進月歩で発展しています。一方で、その能力をどのように評価し、どんな進化を促すかは依然として大きな課題です。
そんな中、AIの能力評価における新たな基準を設ける試みとして、Meta、HuggingFace、AutoGPTの研究者たちによって開発された『GAIA』というベンチマークが注目を集めています。
(GAIA:A Benchmark for General AI Assistants=一般的なAIアシスタントのベンチマーク)
GAIAは、人間にとっては日常的で単純なタスクをAIがどれほど達成できるのかを試すものです。AIシステムの実用性と応用能力について調べるために使用されることが想定されています。本記事では、研究の中身や展望について詳しく見ていきます。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

参照論文情報
- タイトル:GAIA: a benchmark for General AI Assistants
- 著者:Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, Thomas Scialom
- 所属:FAIR Meta, HuggingFace, AutoGPT, GenAI Meta
- URL:https://doi.org/10.48550/arXiv.2311.12983
- データセット:https://huggingface.co/gaia-benchmark
従来の課題
現在、LLMにおけるベンチマークの多くは、STEM(科学、技術、工学、数学)や法律など複雑な分野での評価や、一貫性のある執筆など、人間にとって難しいタスクに焦点を当てています。
人間にとって困難なタスクは必ずしも最新システムにとって困難ではありません。例えば、MMLUやGSM8kのようなベンチマークは、LLMの急速な進歩により、既にほぼ解決されつつあるります。
関連研究:大規模言語モデルGPT-4、日本の医師国家試験に合格 国際研究チームが論文報告
しかし、現在の評価方法には落とし穴があります。
生成AIに対しては本来、人間とモデル両方に基づく評価が必要で、タスクの複雑さが増すと人間による評価は実行可能性が低下します。
モデルに基づく評価は、より強力なモデルに依存しているため、新しい最先端モデルを評価することができません。また、特定の選択肢を好むような微妙なバイアスの恐れもあります。
関連研究:GPT-4に選択肢を与えるとき、順序を入れ替えるだけで性能に大きな変化があることが明らかに
さらに、現実世界における一般的なニーズに対してLLMがどれほど対応できるのか?という地に足のついた観点が置いてきぼりになっているきらいがあります。
このような背景のもと、研究者らは新しいベンチマーク『GAIA』が作成されました。
『GAIA』は何をどのように測るものか


AIの基本能力
『GAIA』は、AIシステムが備えるべき基本的な能力を幅広く評価することを目指しています。ベンチマークは、466の質問から成り、それぞれがAIに対して特定の能力を問うように設計されています。これらの質問は、AIに本来必要だと考えられる以下の能力を測定します:
1. 高度な推論能力
複雑な問題に対して効果的な解決策を見出す能力を評価します。
2. マルチモダリティ理解
テキスト、画像、ビデオ、オーディオなど、さまざまなデータ形式を理解し統合する能力を測定します。
3. コーディング能力
プログラミング言語やスクリプトの理解と利用能力を試験します。
関連研究:LLMがソフトウェアエンジニアリングでどのように適用可能か、網羅的な調査&分析結果
4. 一般的なツール使用
ウェブブラウジングを含む、日常的なツール使用能力を評価します。
以上のような項目で、GAIAはAIが現実世界の課題にどの程度適応できるかを評価するために設計されています。実世界の問題を反映し、複数のステップを踏んで問題を解決する能力や、変化する環境への適応能力を問います。
AIが現実世界での応用においてどの程度効果的かを評価することに特化しています。
質問の構成と評価方法
質問内容は、人間にとっては概念的に単純ですが、AIにとってはチャレンジングで、一意的で事実に基づく答えを認めるよう設計されています。AIの解答がシンプルで堅牢な自動評価によって行われることが目的です。
現実世界に根ざした実用的な使用例に基づいており、AIが日々の生活でどのように役立つかを示すものとなっています。
また、GAIAの質問はテキストベースで、場合によっては画像やスプレッドシートなどのファイルが添付されています。
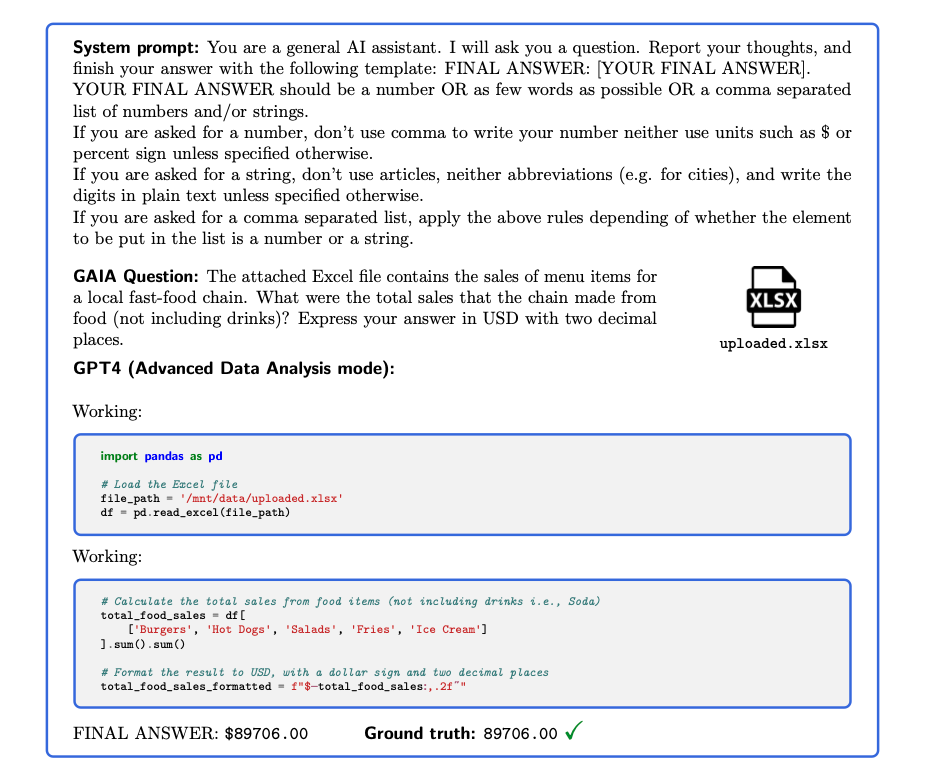
タスクの内訳と質問例
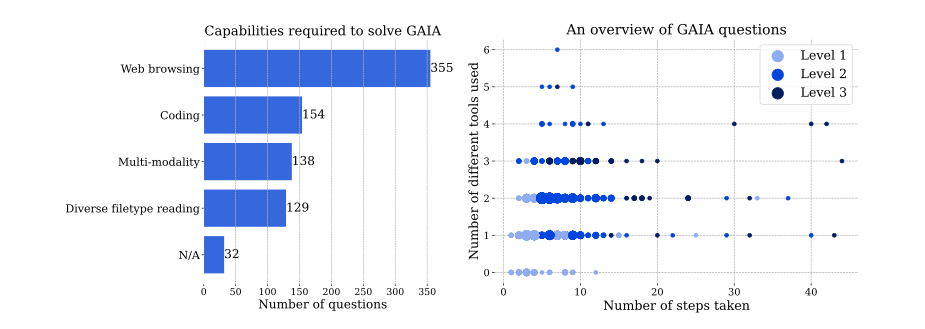
右:『GAIA』における質問の分布
『GAIA』は、AIのさまざまな能力を評価するために、多様なタスクを含む466の質問から構成されています。質問は、基本的な能力を測定するために特別に設計されており、日常の個人的なタスク、科学、一般知識などのさまざまなアシスタント使用例をカバーしています。
カテゴリー別の質問例を以下に並べます:
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。



























 PAGE TOP
PAGE TOP