
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

科学的知識は主に書籍や科学誌に保存されていますが、PDF形式が一般的です。しかし、この形式は特に数学的表現においてセマンティック情報の損失を引き起こします。この問題に対処するために、Meta AIの研究チームは『Nougat(Neural Optical Understanding for Academic Documents)』という新しいOCR(光学式文字認識)技術を開発しました。
Nougatは、数式や文章が複雑に配置された画像であっても、それをマークアップ言語に高品質で変換する能力を持っています。この技術は、新しい論文だけでなく、電子データが存在しない古い書類などの解析にも非常に有用です。
参照論文情報
- タイトル:Nougat: Neural Optical Understanding for Academic Documents
- 著者:Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic
- 所属:Meta AI
- URL:https://doi.org/10.48550/arXiv.2308.13418
- GitHub:https://github.com/facebookresearch/nougat
- デモ:https://facebookresearch.github.io/nougat/
関連研究
研究背景
既存のOCRエンジンの限界
既存の光学式文字認識(OCR)エンジン、例えばTesseract OCRなどは、画像内の個々の文字や単語を検出して分類するのは得意です。しかし、それらの文字や単語の関係性を理解するのは苦手です。これは、行ごとにテキストを処理するアプローチを採用しているためです。
この方法では、上付き文字や下付き文字を周囲のテキストと同じように扱ってしまい、数学的な表現においては大きな欠点を持つことになります。
アクセシビリティと検索性の向上
論文を機械可読なテキストに変換することで、科学全体のアクセシビリティと検索性が向上します。数百万の学術論文の情報は、読み取り不可能な形式に閉じ込められているため、完全にアクセスすることができません。
このような背景から、新たなOCR技術「Nougat」が登場し、注目を集めています。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

今回登場した技術
Noughtの特徴
文字の相対的な位置を正確に認識できる
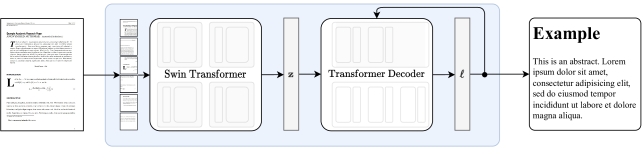
Nougatは、一般的なOCR(光学式文字認識)技術とは異なり、Visual Transformerモデルを採用しています。このモデルは、文書の各部分(文字や数式など)を視覚的に解析し、それらの相対的な位置を正確に認識します。この高度な視覚解析が可能なのは、Swin Transformerエンコーダが文書イメージを潜在的な埋め込みに変換するためです。

特に数学的な表現を認識し整理することに長けている
数学的な表現の解析においても、Nougatは優れています。これは、Swin Transformerエンコーダが数式やその他の複雑なレイアウトを潜在的な埋め込みに変換し、その後でデコーダがこれをトークンのシーケンスに変換するためです。このプロセスにより、数式の各要素(変数、演算子、括弧など)が正確に認識され、適切なマークアップ言語に変換されます。

時系列順の実行プロセス
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。



























 PAGE TOP
PAGE TOP