
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

現行のChatGPTは画像の入出力に対応していませんが、新システム”Visual ChatGPT”によってユーザーはテキストだけでなく画像を通してChatGPTに質問したりタスクを与えることができるようになります。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

マイクロソフトの研究グループが同システムの開発を下記のように報告しています。
人とAIが画像を介して対話する未来
OpenAIによる大規模言語モデル搭載チャットボットChatGPTは、複数の分野やドメインにわたって卓越した会話能力や推論力を持つことが注目されています。しかし、ChatGPTは言語によって訓練され、画像を処理することや生成することは現在(2023年3月9日)できません。一方、Vision TransformerやStable DiffusionなどのVisual Foundation Models(ビジュアル基盤モデル)は、重要な視覚理解や生成能力を持っています。ただし、1ラウンドで入力・出力の特定のタスクを完結するのが通常の機能です。
この課題を解決するため、マイクロソフトの研究グループはVisual ChatGPTというシステムを構築しました。
Visual ChatGPTには、異なるVisual Foundation Modelsが組み合わされており、ユーザーがChatGPTと画像を通して対話する世界を実現します。Visual ChatGPTの特徴は以下の通りです。
1)言語だけでなく画像も送信/受信できる。
2)画像を使用した複雑な質問やタスク命令を多数のステップで可能。
3)フィードバックや修正のリクエストも扱う。
研究グループは、Visual ChatGPTの論文とシステムを公開しています(記事下部に記載)。
Visual ChatGPTの強み
Visual ChatGPTは、言語フォーマット以外でChatGPTとやり取りできるオープンシステムです。今回のプロジェクトでは、Visual Foundation Modelsを使用して、さまざまなタスクをステップバイステップで解決できるように、慎重な設計が行われています。
下記画像でわかるように、実験によって、Visual ChatGPTが多様なタスクに対して優れたポテンシャルを誇っていることが確認されています。
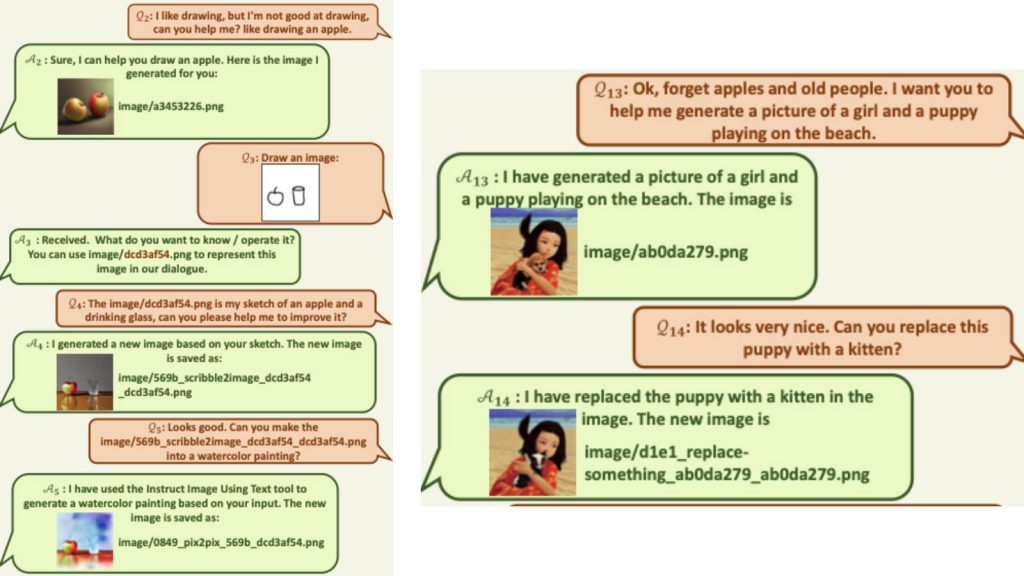

一方、Visual ChatGPTには課題が残っています。
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。



























 PAGE TOP
PAGE TOP