
★AIDB会員限定Discordを開設いたしました!
ログインの上、マイページをご覧ください。
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

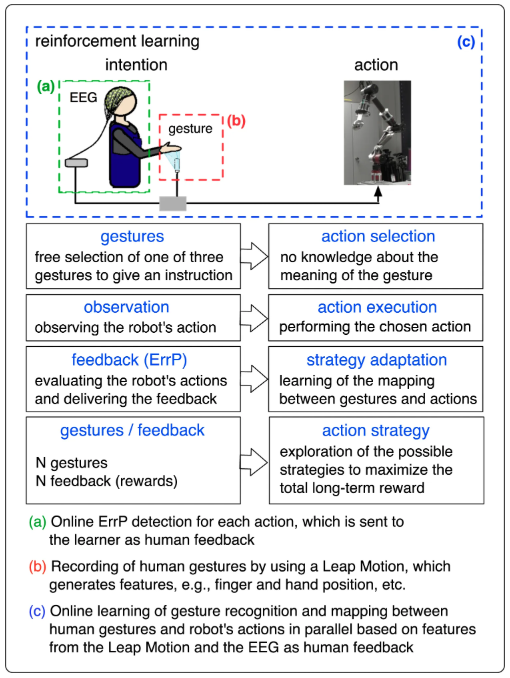
強化学習
強化学習(RL)により、ロボットはフィードバックに基づいて動的環境で最適な行動戦略を学習することができることが発表された。 ロボットRL中の明示的な人間のフィードバックは、明示的な報酬関数を簡単に適応できるため、有利である。 しかし、人間が継続的かつ明示的にフィードバックを生成することは非常に困難で面倒なことであるため、暗黙的なアプローチの開発は非常に重要であると言える。
Su Kyoung Kimら研究者は、RLの本質的に生成された暗黙的なフィードバック(報酬)として、エラー関連電位(ErrP)、人間の脳波(EEG)のイベント関連アクティビティを使用した。
AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

ジェスチャー認識

■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。


























 PAGE TOP
PAGE TOP