

LLMによる複雑な多段階の推論には、なお課題があります。そこで、DeepMindの研究者によって推論の性能を上げる「ステップバック・プロンプティング」が開発されました。本記事ではこの手法の性能に関する実験結果と使用方法を解説します。

ステップバック・プロンプティングは極めてシンプルで具体的なテクニックながら、CoT(Chain-of-Thought prompting)やTake a Deep Breatheといった既存の手法を凌駕する性能を発揮しています。
参照論文情報
・タイトル:Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
・著者:Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, Denny Zhou
・所属:Google DeepMind
・URL:https://doi.org/10.48550/arXiv.2310.06117
従来の課題
LLMはSTEM(科学、技術、工学、数学)や知識ベースの質問応答(Knowledge QA)、多段階推論(Multi-Hop Reasoning)など、複雑なタスクでの使用が増加しています。しかし、これらの高度なタスクにおいて、LLMは中間の推論ステップでの正確性は必ずしも十分ではない場合があります。
既存のプロンプト技術、例えばChain-of-Thought(CoT)プロンプトなどは、中間の推論ステップでの正確性を確かに向上させるものの、分野によっては精度が足りない場合もあります。
簡単に言えば、現在のLLMは「考える過程」でしばしば間違いを犯し、その結果として誤った結論に至る可能性があります。例えば、科学的な問題解決において、LLMは正確なデータ解釈ができない場合があり、それが誤った結論を導く可能性があります。
本記事の関連研究:LLMが真の推論能力を発揮するには時折「一時停止」させるのが重要との報告
ステップバック・プロンプティングの仕組み

そこで今回、DeepMindの研究者らはLLMの推論能力を向上させるための手法としてステップバック・プロンプティングを考案しました。方法論は主に二つのステップで構成されています。
ステップ1: 抽象化
まずは高次の概念や原則(要するに前提)に関する質問を最初に提示することで、特定の詳細から高レベルの概念や原則を導き出します。
問題の詳細を分析: 問題に含まれる具体的な要素や条件を明確にします。
高次の質問を設計: これらの要素や条件から一歩引いて、より高次の概念や原則に関する質問を設計します。
前提の確認: 高次の質問に対する答えを用いて、推論の前提を確立します。
ステップ2: 推論
次に、確認した前提に基づいて、本来の質問における解決策を推論します。
前提の適用: ステップ1で確立した前提を、本来の問題解決に適用します。
論理的推論: 前提に基づき、可能な解決策を論理的に導き出します。
最適な解決策の選定: 複数の解決策が存在する場合、最も効率的かつ効果的なものを選定します。
本記事の関連研究:LLMの出力から誤り(ハルシネーション)を減らす新手法『CoVe(Chain-of-Verification)』と実行プロンプト
従来のプロンプト技術について
Chain of Thought(連鎖的思考)
Chain of Thought(連鎖的思考)とは、問題解決の過程を段階的に進めるように指示するプロンプト技術です。「ステップバイステップで取り組んでください」といった指示プロンプトを与えることによって実行でき、推論の各ステップが明確になります。この方法は、複雑な問題や多段階の推論が必要な場合に有用です。しかし、この技術は中間の推論ステップでエラーが発生する可能性もあります。
Take a Deep Breathe(深呼吸)
Take a Deep Breathe(深呼吸)とは、推論の精度を向上させるためのプロンプト技術です。例えば「深呼吸してから取り組んでください」といった指示プロンプトによって実行できます。モデルがより慎重に問題解決に取り組めるようにするテクニックです。
なお、下記の記事で紹介している論文で初めて明らかにされ、その人間らしさからかなり大きな話題になりました。
LLMが巡回セールスマン問題などの最適化問題を解く〜自分自身で優れたプロンプトを作成&活用〜
これら従来のプロンプト技術は、それぞれ一定の効果を発揮していますが、中間の推論ステップでの正確性が必ずしも高いわけではありません。
性能の検証
対象タスク
この研究では、以下の3つのタスクに焦点を当てています。
- STEM(科学、技術、工学、数学): 高校の物理と化学に関する問題を中心に、モデルの言語理解能力を評価します。
- Knowledge QA(知識ベースの質問応答): TimeQAとSituatedQAという2つのデータセットを使用しています。TimeQAは時間に関連する複雑なクエリを含み、SituatedQAは地理的または時間的な文脈に基づいてモデルが質問に答える必要があります。
- Multi-Hop Reasoning(多段階推論): MuSiQueとStrategyQAというデータセットを使用しています。MuSiQueは単一の質問の組み合わせから作成された多段階の推論を必要とするデータセットであり、StrategyQAは解決に一定の戦略を必要とするオープンドメインの質問を含んでいます。
使用モデル
研究では、次の2つの最先端の大規模言語モデルを使用しています。
- PaLM-2L: 基本モデルと調整済みモデルの2種類がテストされています。
- GPT-4: OpenAIによって開発されたこのモデルも実験に使用されています。
評価指標
本記事の関連研究:LLMが巡回セールスマン問題などの最適化問題を解く〜自分自身で優れたプロンプトを作成&活用〜
実験の結果
性能向上の範囲
論文によれば、ステップバック・プロンプティングは各ベンチマークで7%から27%の性能向上を達成しました。
従来のプロンプト技術との比較
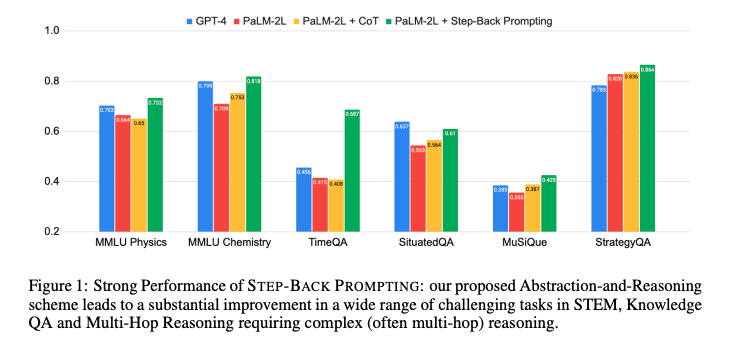
ステップバック・プロンプティングは、従来のプロンプト技術であるChain of Thought(CoT)とTake a Deep Breathe(TDB)と比較しても、最も高い性能を発揮しました。CoTやTDBのゼロショットプロンプティングは、ベースラインモデルの性能を大幅に向上させることはありませんでした。一方で、ステップバック・プロンプティングは、PaLM-2LとGPT-4といった先進的なLLMに対しても高い性能を発揮しました。
タスクの難易度と性能
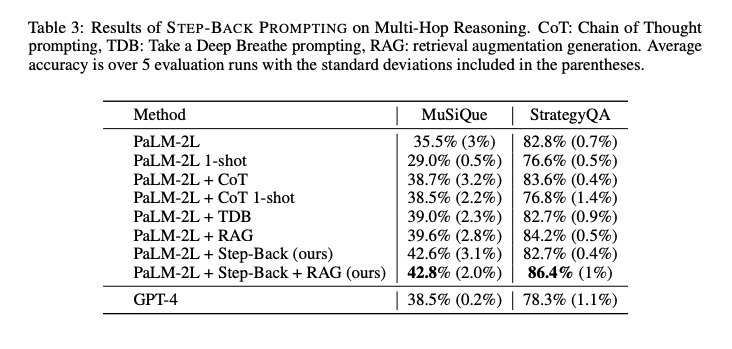
論文では、難易度の高いタスクにおいてもステップバック・プロンプティングが有効であることが示されました。例えば、TimeQAというタスクにおいて、ステップバック・プロンプティングは、高レベルの概念に基づいて最終的な推論を行うことで、精度を大幅に向上させました。
ただし、ステップバック・プロンプティングも完璧ではありません。論文内でのエラー分析によれば、一部のエラーは依然として存在します。しかし、その数は従来の方法よりも少なく、特に高レベルの抽象概念に基づいた推論においては、その有用性が確認されました。
本記事の関連研究:推論能力をさらに強める戦略『AoT』で、LLMが「直感」に似た能力を示すようになった
プロンプト例
このセクションでは、ステップバック・プロンプティングを使用した際の具体的なプロンプト例を示します。
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。










 PAGE TOP
PAGE TOP