
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

最終更新日:2021/07/27
人型ロボット完成へのロードマップ
人間のように動作するロボットを作ることは、ロボット工学の壮大な課題です。機械学習は、ロボットを手動でプログラミングする代わりに、センサ情報を用いてロボットシステムを適切に制御する方法を学習することで、これを実現する可能性を秘めています。
学習には膨大な量の学習データが必要ですが、物理的なシステム上でそれを取得するのは難しく、コストもかかります。そのため、すべてのデータをシミュレーションで収集する手法が注目されています。
しかし、シミュレーションは実行環境やロボットを細部まで正確に捉えているわけではないため、結果として生じるシミュレーションのデータを現実へ変換させる問題も解決する必要があります。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

ロボットに人間のような動作をさせる課題において、実際にどんな研究が行われているのでしょうか。OpenAIのIlge Akkayaら研究者の発表を紹介します。
研究者らは、コンピュータ上でシミュレーションしたロボットアームの動きを現実に利用することで、人間のような動きをするロボットの製作を試みました。
▼論文情報
著者:Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, Jonas Schneider, Nikolas Tezak,
Jerry Tworek, Peter Welinder, Lilian Weng, Qiming Yuan, Wojciech Zaremba, Lei Zhang
タイトル:”SOLVING RUBIK’S CUBE WITH A ROBOT HAND”
arXiv
URL:DOI
シミュレーションと現実世界を行き来する
まずはAkkayaらの研究におけるミッション・手法・結果をまとめました。
|
✔️ミッション ✔️解決手法 ✔️結果 |
ミッションから説明していきます。
シミュレーションのデータを現実のロボットに適用させる
ドメインランダム化技術は大きな可能性を秘めており、シミュレーションのみで訓練されたモデルが実際のロボットシステムに移植できることを実証しています。
先行研究では、ブロックを手の中で複雑に操作することができることを実証しました。
Akkayaらは、Shadow Dexterous Hand(ロボットアーム) でルービックキューブを解くために必要な操作と状態推定の問題を、シミュレーションデータのみを用いて解決することを目指しました。
ルービックキューブを解くためには、キューブの姿勢や内部状態を高い精度で知る必要があります。
本研究では、強化学習の方針や視覚情報による状態推定器を学習するために、ランダム化された環境の分布を自動的に生成する新しい手法を導入することで、これを実現しています。このアルゴリズムをADR(Automatic Domain Randomization:自動ドメインランダム化)と呼んでいます。
また、Akkayaらは自身の機械学習アプローチを補完する形で、実世界でルービックキューブを解くためのロボットプラットフォームを構築しました。図1にシステムの概要を示します。
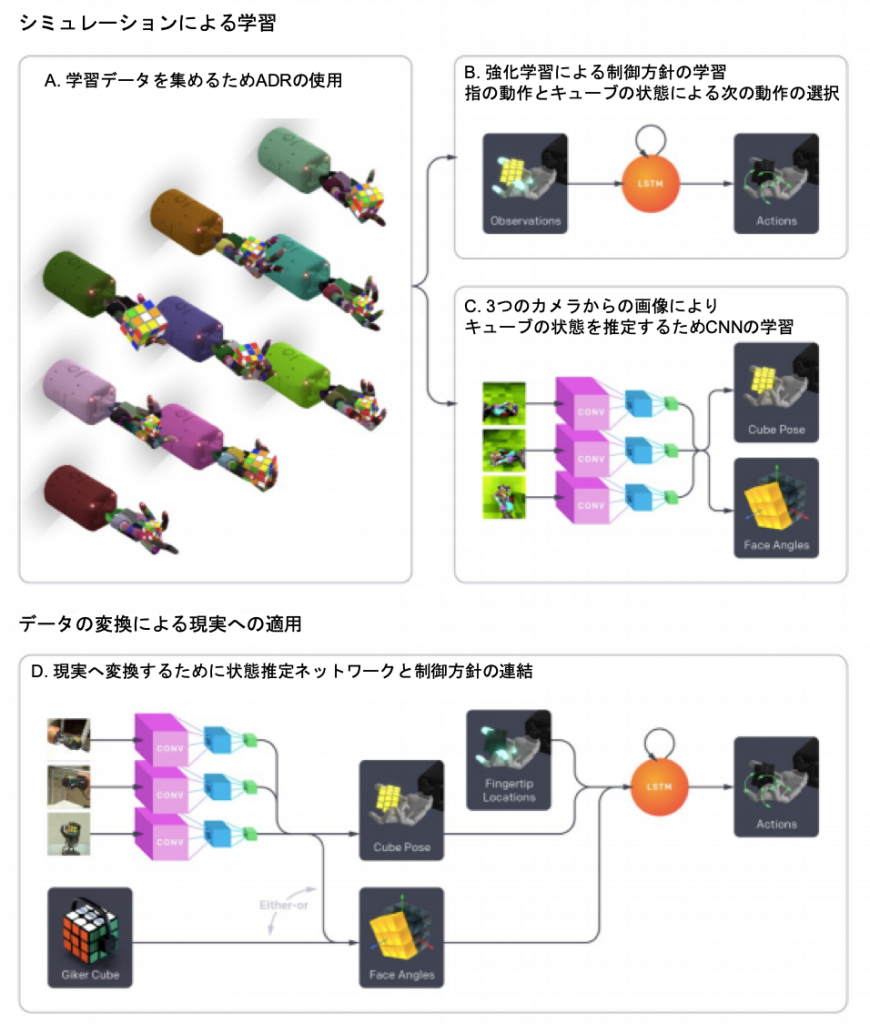

自動ドメインランダム化を用いた訓練による2タスクの実験
Akkayaらは、自動ドメインランダム化の手法を用いて2つのタスクをシミュレーションで訓練させたのち、現実のロボットで適用させました。
タスク
本研究では、ロボットアームを使用する2つの異なるタスクを検討します。すなわち、ブロックの向き変更タスクとルービックキューブを解くタスクです。両タスクを図2に示します。

向き変更タスク
このタスクの目的は、ブロックを所望の目標方向に回転させることです。
ブロックの回転がゴールの回転と0.4ラジアン以内で一致すれば、ゴールが達成されたとみなされます。
ゴールが達成されると、新しいランダムなゴールが生成されます。
ルービックキューブを解くタスク
ここでは、「回転」と「反転」の2種類のサブゴールを考えます。「回転」は、ルービックキューブの1つの面を時計回りまたは反時計回りに90度回転させること、「反転」は、ルービックキューブの別の面を一番上に移動させることです。一番上の面を回転させるのは他の面を回転させるよりもはるかに簡単であるため、反転と上面の回転を組み合わせて、目的の操作を行います。これらのサブゴールを順次実行していくことで、最終的にルービックキューブを解きます。
ルービックキューブを解く難易度は、スクランブルがかかっているかどうかで決まります。ここでは、World Cube Association3 が公式に採用しているスクランブル方法を用いました。公正なスクランブルとは、通常、解いた状態のルービックキューブに約20回の操作を加えるものです。
ルービックキューブの状態を視覚だけで検知することは、非常に困難です。そこで、センサーとBluetoothモジュールが内蔵された「スマート」なルービックキューブ、Xiaomi社のGiikerキューブを採用しています。
しかし、このキューブは90度の角度分解能しかなく、状態を追跡するには十分ではありません。そこで、オリジナルのGiikerキューブの部品の一部をカスタム部品に置き換え、約5°のトラッキング精度を実現しました。
シミュレーション
物理エンジンMuJoCoを用いて物理システムをシミュレートし、Unity3D上に構築されたリモートレンダリングバックエンドを用いて、視覚ベースの姿勢推定器を学習するための合成画像をレンダリングしました。
アームの動きの較正
アームが自由に動ける環境で、現実の手とシミュレーション上の手の同じ時系列の動作について関節位置を測定し、以下の2つが観測されました。
1. 現実のロボットで記録した関節位置とシミュレーションで記録した関節位置が目に見えて異なる。
2. 結合関節(親指以外の指の遠位2関節)のダイナミクスが、現実のロボットとシミュレーションでは異なる。
シミュレーションでは、結合関節の動きは2本の固定された腱でモデル化されており、1回の動作で両方の関節がほぼ同じ距離を移動することになっていました。しかし、現実のロボットは、結合関節の動きは各関節の現在の位置に依存します。例えば、人間の手のように、指を曲げるときには、指の近位部が遠位部よりも先に曲がるようになっています。
そこで、親指以外の指に、実際のロボットに存在する非作動式の腱と同じように非作動式の空間的な腱と滑車を追加しました(図3参照)。

親指以外の各指には、空間的な腱(緑の線)と滑車の役割を果たす2つの円筒形(黄色の円筒)が追加され、実際のロボットと同様の結合関節ダイナミクスを実現しています
ルービックキューブ
ルービックキューブは非常に複雑な構造で、要素間の相互作用は非自明です。
立方体を構成する各要素は常に互いに圧力をかけ合っており、立方体間や結合部のシステムには一定の基本的な摩擦が生じています。1つの面を回転させるためには、1つのキューブレットに力を加えるだけで十分であり、その力は接触力を介して隣接する要素間に伝播します。立方体には回転可能な6つの面がありますが、すべての面を同時に回転させることはできません。1つの面がすでに一定の角度だけ動かされていると、直交する面はロック状態になり、動かせなくなります。しかし、この角度が十分に小さい場合、元の面はしばしば「スナップ」して最も近い整列状態に戻り、垂直な面の回転を進めることができます。
シミュレーションでのトレーニングから現実への移行を成功させる必要があるため、ソフトウェアの複雑さと計算コストを管理可能な状態に保ちつつ、前述のすべての動作を含むことができるモデルを作成する必要があります。Akkayaらは、ソフトコンタクトを伴うボディダイナミクスをシミュレーションするために安定した高速な数値解法を実装した物理エンジンMuJoCoを使用しました。
物理的な立方体にヒントを得て、シミュレーションモデルは26個の剛体凸型立方体で構成されています。各面の中央の6個の立方体には1つのヒンジジョイントがあり、各面に直交する立方体の中心を通る軸に対して1つの回転自由度を持っています。残りの20個のキューブレットは、キューブの中心を通る回転軸を持つ、完全なオイラー角表現に対応する3つのヒンジジョイントを持っています。これにより、6×1+20×3=66の自由度を持ち、物理的に有効なすべての中間状態を効果的に表現することができます。
自動ドメインランダム化(ADR:Automatic Domain Randomization)
先行研究では、ドメインランダム化を用いてシミュレーションで制御方針と視覚モデルを学習し、その両方を実際のロボットに移植することができました。しかし、この方法では膨大な量のパラメータを手動で調整する必要があり、シミュレーションでのランダム化の設計とロボットでの検証との間に緊密な反復ループが必要でした。
ADR(Automatic Domain Randomization)はシミュレーションの自動化と、制御方針と視覚モデルのトレーニングに適用します。
ADR使用の動機となる仮説は、”最大限に多様な環境の分布でトレーニングを行うことで、創発的なメタ学習を介して伝達が行われる”というものです。具体的には、モデルが何らかの形で記憶を持っていれば、現在の環境でのパフォーマンスを時間をかけて改善するために、展開中の行動を調整することを学習することができます。このようなことが起こるのは、学習分布が非常に大きく、モデルが有限の容量を持っているために環境ごとの特別な目的のソリューションを記憶できない場合であると仮説を立てています。ADRは、環境の複雑さが制限されない方向への第一歩です。環境上の分布をパラメータ化するランダム化の範囲を自動化し、徐々に拡大していきます。
ADR の概要
ADR は視覚モデルの学習(教師付き学習)と制御方針の学習(強化学習)の両方に使用します。いずれの場合も、立方体の外観やロボットハンドのダイナミクスなどをランダム化することで、環境に関する分布を生成します。ドメインランダム化(DR)では、この分布の範囲を手動で定義し、モデルの学習中は固定しておく必要がありますが、ADRでは分布の範囲は自動的に定義され、変更することができます。
図4にADRの概要を示します。
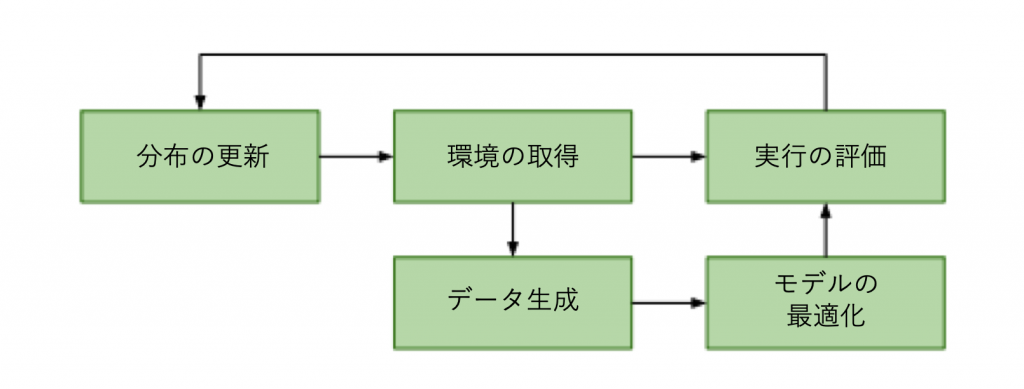
ADR は環境の分布を制御します。この分布から環境を取得(サンプリング)し、それを使ってトレーニングデータを生成し、モデル(制御方針または視覚状態の推定値)を最適化します。さらに、現在の分布におけるモデルの性能を評価し、この情報を使って環境の分布を自動的に更新します。
以下にADRの直感的な概要を示します。
ADR は、モデルが優れた性能を発揮できる環境の分布を徐々に拡大していくトレーニングカリキュラムを実現します。最初の環境の分布は、1つの環境に集中しています。例えば、制御方針トレーニングでは、初期環境は現実のロボットから測定された較正値に基づいています。環境の分布は、学習データの生成やモデルの性能評価に使用される環境を得るためにサンプリングされます。ADRは、モデルの学習に使用されるアルゴリズムに依存しません。トレーニングデータを生成するだけです。これにより、ADRを制御方針モデルと視覚モデルの両方のトレーニングに使用することができます。
学習が進み、初期環境でのモデル性能が十分に向上すると、分布が拡張されます。この拡張は、モデルの性能が許容できると考えられる限り続けられます。十分に強力なモデルアーキテクチャとトレーニングアルゴリズムがあれば、モデルの性能が向上するたびにランダム化が増加するため、分布は手動によるドメインランダム化の範囲をはるかに超えて拡大すると予想されます。
ADRには、2つのメリットがあります。
- トレーニングが進むにつれて徐々に難易度を上げていくカリキュラムを使用することで、トレーニングが簡素化されます。これは、問題が最初に単一の環境で解決され、最低レベルのパフォーマンスが達成されたときにのみ環境が追加されるためです。
- ランダム化を手動で調整する必要がありません。ランダム化パラメータの数が増えると手動での調整がますます困難になり、直感的ではなくなってしまいます。
制御方針トレーニングシミュレーション
行動、報酬、および目標
トレーニングの際にエージェントに与える報酬には3種類あります。
(a)システム状態のゴール状態からの前回と今回の距離の差
(b)ゴールが達成されるたびに5の追加報酬
(c)キューブやブロックが落とされるたびに-20のペナルティ
トレーニング中にランダムなゴールを生成します。ブロックの場合、目標の回転はランダムにサンプリングされますが、どの面も真上を向くように制約されます。ルービックキューブの場合は、ゴールが生成された時点でのキューブの状態に依存するため、タスクの生成は複雑になります。キューブの面が揃っていない場合は、必ず面を揃え、さらにブロックと同じようにサンプリングされたランダムな向きでキューブ全体を回転させます(フリップ)。また、面が揃っている場合は、一番上の立方体の面を50%の確率で時計回りまたは反時計回りに回転させます。そうでなければ、再びフリップを行います。
以下の条件のいずれかが満たされたときに、トレーニングエピソードが終了したとみなします。
- エージェントが50回連続して成功する(必要な閾値内でゴールに到達した)
- エージェントがキューブを落とす
- またはエージェントが次のゴールに到達しようとしてタイムアウトする
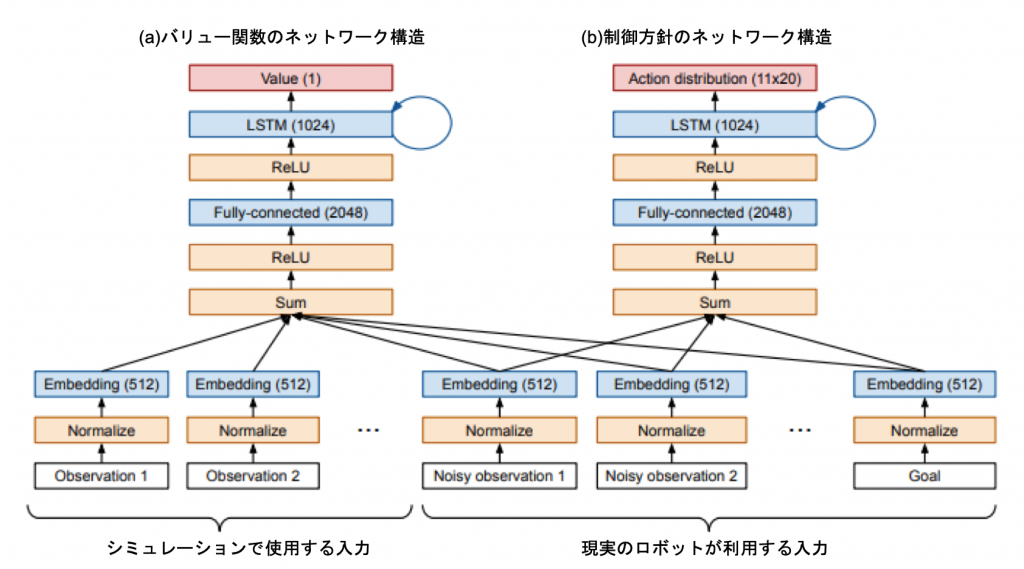
制御方針アーキテクチャ
ReLU活性化を用いた単一のフィードフォワード層と、それに続く単一のLSTM層を使用しています。
バリューネットワークは制御方針ネットワークとは別のもので、LSTMの出力をスカラー値に投影します。
Akkayaらのネットワークアーキテクチャは、図5に示します。
クローニング
ADRでは、常に挑戦的なトレーニング分布を持つことができるため、同じ方針を非常に長い時間トレーニングすることが有用であることがわかりました。そのため、実験をゼロからトレーニングすることはほとんどなく、既存の実験を更新し、ADR と方針のパラメータの両方について以前のチェックポイントから初期化しました。初期化されていないモデルからトレーニングを再開すると、数週間から数ヶ月のトレーニングの進捗が失われてしまうため、非常にコストがかかります。
複製の設定は、教師と生徒の両方の方針がメモリにロードされていることを除けば、強化学習に近いものとなっています。実行の際には、生徒の行動を使って環境と対話しながら、生徒と教師の行動分布の差を最小化し、値の予測を最小化します。これは驚くほどうまく機能しており、蓄積されたトレーニングの進捗を失うことなく、制御方針アーキテクチャを素早く反復することができます。このクローニング手法は、行動空間が変わらない限り、任意のポリシーアーキテクチャの変更にも対応します。
今回使用した最良のADRポリシーは、この方法で得られました。モデルアーキテクチャ、学習環境、ハイパーパラメータを何度も変更しながら、複数月にわたって学習を行いました。
視覚情報からの状態推定
本研究では、ルービックキューブの状態を推定するために、2つの異なるオプションを使用しています。
1. 非対称のセンターステッカーによる視覚情報
この場合、視覚モデルを使用して、キューブの位置、回転、および6つの面の角度を生成します。これにより、回転の対称性が崩れ、1つのフレームから絶対的な顔の角度を決定することができます。ルービックキューブには、これ以上のカスタマイズはしません。このモデルを使用して、ルービックキューブを解くための視覚情報のみの手法の最終的な性能を推定しました。
2.姿勢の把握には視覚情報、面の角度の把握にはGiikerキューブを使用
このケースでは、ビジョンモデルはキューブの位置と回転を生成するために使用されます。面の角度については、センサー内蔵のカスタマイズされたGiikerキューブを使用しています。ほとんどの実験でこのモデルを使用しているのは、視覚のみからの難しい面の角度推定の誤差と、方針の誤差が重ならないようにするためです。
ビジョンモデル
Akkayaらのビジョンモデルは、ケージの左、右、上部に設置された3台のカメラからの画像を入力としています(図6参照)。

モデル全体のアーキテクチャを図7に示します。各画像は、パラメータが同一のResNet50ネットワークで処理して、特徴量マップを作成します。これらの3つの特徴マップは、フラット化され、連結され、完全に接続された層のスタックに供給され、最終的に、位置、向き、面の角度など、キューブの完全な状態を追跡するのに十分な予測値を生成します。
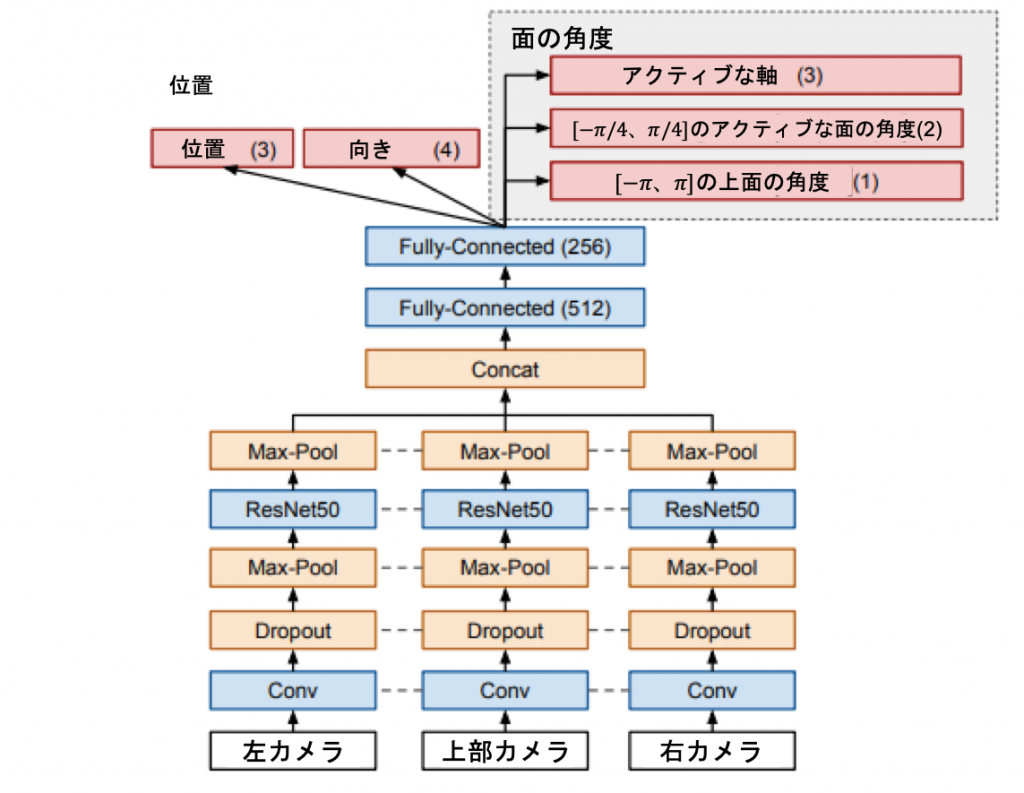
位置と向きを直接予測することはうまくいきますが、6つの面の角度を直接予測することは、非対称なセンターステッカーを持つキューブを使用した場合でも、オクルージョンが多いために非常に困難であることがわかりました。この問題を解決するために、Akkayaらは面の角度の予測をいくつかの異なる予測に分割しました。
1. アクティブな軸
キューブの3つの軸のうち1つだけが「アクティブ」(つまり非整列状態)であるという単純化された仮定を置き、モデルに3つの軸のうちどれが現在アクティブであるかを予測させます。
2. アクティブな面の角度
アクティブな軸に関連する2つの面の角度をπ/2ラジアン(つまり[-π/4, π/4])に修正して予測します。[-π/4, π/4]の絶対角度は、物体の重なりが多いため、直接予測することは困難です(例えば、面が下にあり、手のひらで隠れている場合など)。角度を予測するには、キューブの形状とエッジの相対的な位置を認識するだけなので、より簡単な作業となります。
3. 上面の角度
最後に予測するのは、手の真上に設置されたカメラから見える「上面」の絶対的な角度を[-π, π]ラジアンで表します。上面のセンターキューブレットはほとんどオクルージョンがないため、上の面だけを予測するようにモデルを構成します。これにより、各面の絶対的な回転角度が、その面が一番上に置かれたときに、静的に推定されます。
これらの面の角度予測は、後処理ロジックに与えられ、すべての面の角度の回転を追跡し、その結果が方針に伝えられます。上面の角度の予測は特に重要で、トラッキングされた絶対的な面の角度の状態を実行の途中で修正することができます。例えば、ある面の角度のトラッキングが回転数(π/2ラジアンの倍数)だけずれてしまった場合でも、フリップ後にその面が上部に置かれるたびに、モデルからのステートレスな絶対角度予測によって修正することができます。
ロボットアームによる複雑なタスク処理に成功
結果、従来の手法よりも高精度で2つのタスクを現実に解くことに成功しました。
ADR が制御方針の伝達に与える影響
ADRを使って制御方針を訓練することによる変換性能への影響を理解するために、単純なブロック再配置タスクで問題を研究しました。このタスクは計算が容易であり、ベースライン性能が確立されています。性能は連続した成功の数で測定します。ブロックが落ちるか、50回連続で成功した場合に試行を終了します。したがって、最適なポリシーは、平均50回の成功を達成するポリシーとなります。
Sim2Sim
まず、シミュレーションのデータをシミュレーションに適用させるケースを考えます。具体的には、ADR で方針を学習し、手動で調整されたランダム化を持つ環境の分布で、そのパフォーマンスを継続的に評価します。なお、この分布で直接ADR実験を行ったことはありません。代わりにADRを使用して訓練する分布を決定し、手動で設計された環境上の分布をSim2Sim変換のテストセットにします。その結果を図8に示します。

図8に見られるように、ADRでトレーニングした方針は、手動でランダム化した分布に移行します。さらに、ADR が無作為化エントロピーを増加させると、Sim2Sim変換のパフォーマンスが向上します。
Sim2Real
次に、Sim2Real変換能力を評価します。ロボットでの実行はコストがかかるため、評価するポリシーは7種類に限定しました。それぞれのポリシーについて、ロボット上で合計10回の試行を行い、連続して成功した回数を測定します。前述のように、50回成功するか、ロボットがタイムアウトするか、ブロックが落とされるかのいずれかで試行は終了します。結果を表1にまとめます。
表1 ブロック再配置タスクにおける異なる方針のパフォーマンス
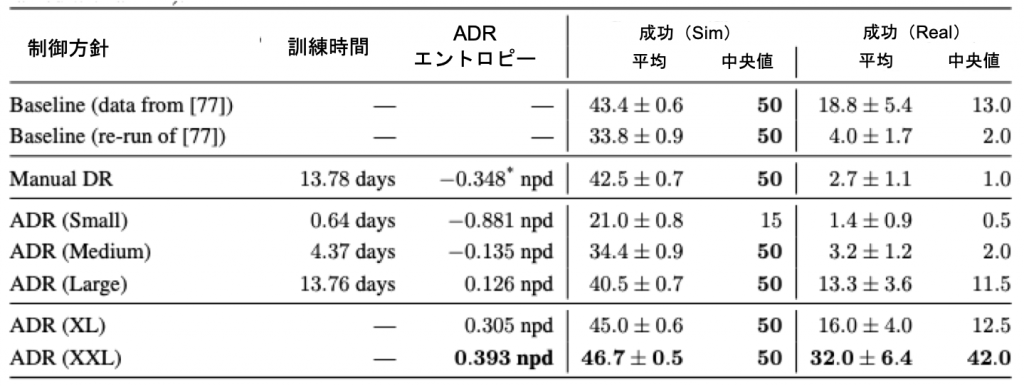
表の最後のブロックは、ADR をスケールアップした際に得られた結果を示しています。ここでは「ADR (XL)」と「ADR (XXL)」の結果を報告します。これは、長期間にわたって継続的にトレーニングされ、より大きなスケールで行われた2つの実験を指しています。これらの実験では、最高の sim2sim および sim2real 転送が行われ、ADR エントロピーの増加が sim2real 転送の大幅な改善に対応していることがわかりました。平均値で約2倍、中央値で3倍以上の性能向上を実現しましたが、Akkayaらの先行研究で報告されたベースラインを大きく上回りました。
ADR で学習したポリシーは、最終的にSim2Sim転送でもほぼ完璧なパフォーマンスを達成しています。
要約すると、ADR は明らかに、手作業によるランダム化の必要性を大幅に減らして、転送を改善します。この結果は、数ヶ月に及ぶ反復的な手動チューニングの結果である、先行研究の最高の結果を大幅に上回りました。
ポリシートレーニングにおけるカリキュラムの効果
ADRでは、トレーニング分布の複雑さを徐々に拡大するように設計しました。つまり、1つの環境から始めて、エージェントの進歩に合わせて環境の分布を増やしていきます。その結果、最終的には非常に多様な環境をマスターできるようなカリキュラムになるはずです。しかし、このカリキュラムの特性が重要なのか、あるいは、一度見つけたドメインランダム化パラメータの固定セットでトレーニングできるのかは明らかではありません。
これを検証するために、次のような実験を行います。ブロック再配置タスクでADRを用いて1つのポリシーを学習し、異なる固定ランダム化を用いた複数のポリシーと比較します。固定レベルは、small、medium、large、XLの4種類を使用します。これらは、表1のADRのパラメータに対応しています。これらのパラメータを使って新しいポリシーをゼロから訓練し、すべての方針を等しい時間で訓練します。すべてのポリシーのパフォーマンスを、手動でランダム化された分布で継続的に評価し、すべてのケースでSim2Sim変換をテストします。その結果を図9に示します。

すべてのDRの実行において、ランダム化エントロピーは一定で、ADRのものだけが徐々に増加していることに注意してください。
図9の結果は、ランダム化エントロピーを適応的に増加させることが重要であることを明確に示しています。ADRの実行では、ランダム化エントロピーを固定した他のすべての実行よりもはるかに早く高いSim2Sim変換量を達成しています。また、固定されたランダム化エントロピーが大きいほど、ゼロからのトレーニングにかかる時間が長くなるという明確なパターンがあります。
ビジョンモデルの性能に対する ADR の影響
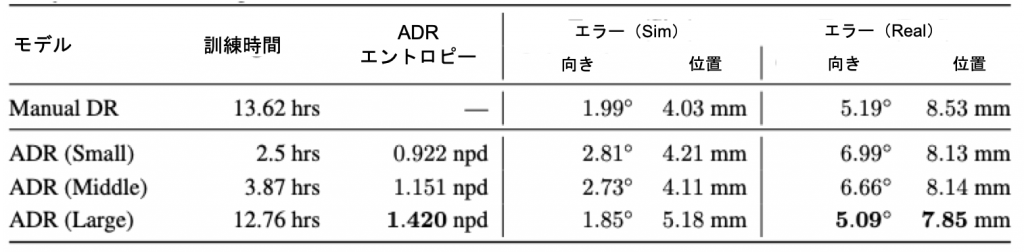
ビジョンモデルを学習する際、ADRはORRBのランダム化の範囲(光の距離、素材のメタリック度、光沢度など)とTensorFlowの歪み操作(ガウスノイズやチャンネルノイズの追加など)の両方を制御します。ブロック再配置タスクとルービックキューブタスクの両方について、ADRで強化されたビジョンモデルを訓練して状態推定を行います。表2に示すように、ブロックの向きと位置の両方に関する予測誤差を、手動によるドメインランダム化の結果よりもさらに低減させることができました。
表2 ブロック再配置状態推定タスクにおけるADRエントロピーレベルを変えたビジョンモデルの性能
ルービックキューブの完全な状態を予測することはより困難なタスクであり、より長いトレーニング時間を必要とします。表3に示すように、ADRを使用したビジョンモデルは、同程度の学習時間であれば、手動でDRを設定したベースラインモデルよりも低いエラーを達成することができます。
表3 ルービックキューブ予測課題におけるADRエントロピーレベルの異なる視覚モデルの性能
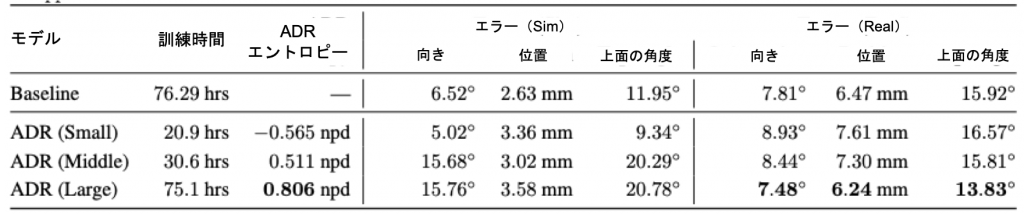
ADR のエントロピーの高さは、実画像でのエラーの低さとよく相関しています。ADR は今回も手動で調整したランダム化(ベースライン)を上回りました。ただ、ADR がより困難な合成タスクを生成すると、シミュレーションのエラーは増加します。
ルービックキューブ
定量的な結果
ここでは、次の 4 種類のポリシーを比較しました。手動ドメイン・ランダム化(Manual DR)を約 2 週間学習した方針と、ADR を用いて約 2 週間学習した方針、そして ADR を用いて継続的に学習・更新した 2 つの つの方針を比較しました。
パフォーマンスを評価するために、一定の手順を定義し、各方針ごとに10回の試行を行いました。具体的には、常にキューブが解けた状態からスタートし、手にルービックキューブを公平なスクランブル状態に移動させるように指示します。これは、問題が左右対称であることから、公平にスクランブルされたルービックキューブの状態から解いていくことと同じです。しかし、正しい初期状態を確保することは、ルービックキューブが解かれている場合よりもはるかに単純なことなので、人為的なミスや労力の発生確率を大幅に減らすことができます。
成功回数が50回に達した時点で試験を終了します。キューブが落とされた場合、あるいは1600タイムステップ(128秒に相当)以内にゴールに到達できなかった場合、試行は終了します。
各試行において、成功裏に達成されたゴール (反転と回転の両方) の数を測定します。また、2つのしきい値を設定しました。公正なスクランブルの半分以上を成功させた場合(すなわち22回の成功)と、公正なスクランブル全体を成功させた場合(すなわち1回の成功)です。スクランブルの半分以上が成功した場合(22回)と、スクランブルの全部が成功した場合(43回)です。両者の成功率は、10回の試行を平均して、「half」と「full」と表記しました。「full」のしきい値を達成することは、ルービックキューブを解くことと同じです。結果の概要を表6に示します。
表4 異なる方針におけるルービックキューブタスクのパフォーマンス
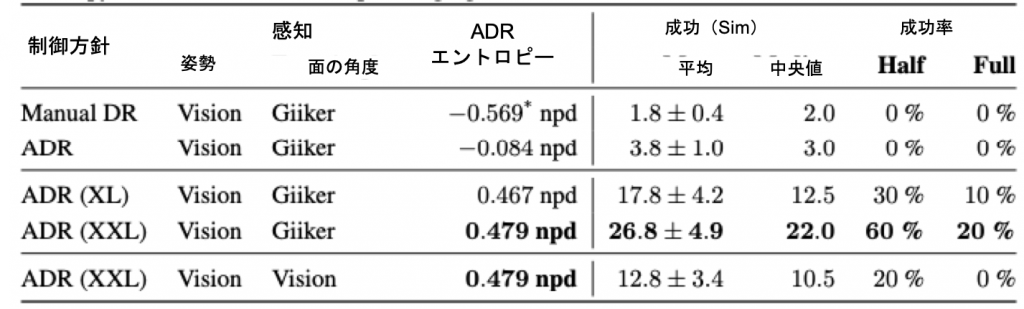
これまでの結果と同様に、手動によるドメインのランダム化は失敗しました。ADRで学習したポリシーでは ADRを用いて学習したポリシーについては、シミュレーションによる移行は、次元ごとのエントロピーに明らかに依存していることがわかります。「手動DR」と「ADR」は 「手動DR」と「ADR」は、通常の1/4の計算量で14日間学習されましたが、完全に比較可能です。最善の方針は、10回の試行で平均26.80回の成功を達成しました。これは、15回の面の回転を必要とするルービックキューブを60%の確率で解くことができることに相当します。
定性的結果
ルービックキューブを解くのに最適なポリシー(ADR(XXL))を使用したとき、ロボットには多くの興味深い行動が見られました。Akkayaらが記録したノーカットのビデオ映像を視聴することが可能です。
例えば、ロボットが誤って間違った面を回転させてしまうことがあります。このような場合、まず面を回転させてから元のサブゴールを追求することで、サブゴールを変更することなく、このミスから回復することができます。また、ロボットはフリップを実行した後、回転を試みる前に面を整列させることで、ミスアライメントによる連動を回避しています。しかし、面を回転させるのは難しい場合があり、ロボットが動けなくなってしまうことがあります。このような場合、ポリシーは最終的に把持力を調整して別の方法で面の回転を試みるため、最終的に成功することが多いです。また、面を回転させようとしても、キューブが滑ってしまい、特定の顔ではなく、キューブ全体が回転してしまうこともあります。この場合、ポリシーは把持部を再配置して再挑戦し、最終的には成功します。
また、困難な面の回転にしばらく立ち往生していると、キューブを落とす可能性が高くなることも観察されました。方針のリカレント状態では、ほとんど静止した立方体を数秒間観察しただけなので、それまでに反転を「忘れてしまった」のではないかと考えられます。反転の場合は、キューブのダイナミクス特性に関する情報がより重要になります。同様に、初期の段階ではポリシーがキューブを落とす可能性が高いことも観察されました。これも、キューブの動的特性に関する必要な情報がポリシーの隠れた状態でまだ捕捉されていないためと考えられます。
また、いくつかの摂動を試してみました。例えば、ゴム製の手袋を使って、手の摩擦や表面の形状を大きく変える。ストラップを使って、複数の指を束ねる。実行中の手とルービックキューブを毛布で隠す。ペンとキリンのぬいぐるみを使ってルービックキューブを突く。これらの実験では数値化していませんが、明らかに学習していないにもかかわらず、これらの条件でもポリシーは複数の面の回転やキューブの反転を行うことができることがわかります。これらの摂動下での動作を示すビデオも視聴可能です。
シミュレーションのための強力なアルゴリズムであるADR(Automatic Domain Randomization)は、視覚と制御の両方に手動でドメインランダム化を行う従来のベースラインよりも精度が改善されることを示しています。さらに、ADRとカスタムロボットプラットフォームを組み合わせることで、人型ロボットがルービックキューブを解くという、これまでにない複雑な操作問題に成功しました。ADRで学習した方針は、再帰的な状態の更新によって、現実に展開時に適応することができます。
研究紹介は以上です。
ソフトの進化に応じて、ハードの性能もどんどん進化していきますね。
さらに人間のような動きをするロボットが登場することを期待したいです。
関連記事




■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。



























 PAGE TOP
PAGE TOP