
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

最終更新日:2021/07/02
高速な判定へ
チューリングテストは、ある機械が人間的であるかどうかを判定するテストです。一般的にチューリングテストは、人間的であることを人間自身が判断します。人間的であると判定されるようなエージェントを開発するためには、迅速かつ正確に、行動を数式化・定量化する必要があります。
勿論、チューリングテストは人間が行うため、かなり正確な結果が得られますが、高速に判定を行うことは難しいです。では、このチューリングテストを自動化するとどうなるでしょうか。信頼性のある結果が得られれば良いですが、人間の感性に合致していないモデルが生成されうる可能性もあります。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

チューリングテストにおける迅速に判定できないという課題において、実際にどのような研究が行われているのでしょうか。Microsoftの研究者の発表を紹介します。
研究者らは、複数のネットワークを用いることによって、人間的であるかどうかの分類器を作成しました。
▼論文情報
著者:Sam Devlin, Raluca Georgescu, Ida Momennejad, Jaroslaw Rzepecki, Evelyn Zuniga, Gavin Costello, Guy Leroy, Ali Shaw and Katja Hofmann
タイトル:”Navigation Turing Test (NTT): Learning to Evaluate Human-Like Navigation”
arxiv
URL:DOI
人間的な判断の学習と評価
まずはMicrosoftの研究者らの研究におけるミッション・手法・結果をまとめました。
|
✔️ミッション ✔️解決手法 ✔️結果 |
ミッションから説明していきます。
自動ナビゲーションチューリングテスト
チューリングテストの目的は、「機械が人間的な振る舞いを行えるかどうか」を知ることです。最終的には汎用型AIの開発につながるでしょう。しかしながら、人間的な振る舞いをするエージェントの開発はまだなされていません。
Microsoftの研究者らは、自動ナビゲーションチューリングテスト(ANTT: automated Navigation Turing Test)を提案しました。このシステムは、人間的な行動を自動的に判断してくれるものです。従来のチューリングテストでは人間的な振る舞いを人間が判断していました。これには判断速度が遅いという問題点があります。この問題を解決するために、このシステムを提案したのです。
人間的であるかどうかの判断を行うモデルとは
Microsoftの研究者らは、複数のネットワークを用いて、人間的であるかどうかの判断を予測するモデルを構築しました。
研究者らが構築したモデルは、観測された行動が人間的であるか人間の判断を予測する分類タスクです。例えば、ゲームのプレイヤーがbotであるかどうかを判定するタスクを考えましょう。これはチューリングテストとみなせます。ここでは、プレイヤーがbotであるかどうかに関係なく、人間が判断した結果が正解となります。
分類モデルの作成
最初に、このモデルの概要をまとめます。
- 目的: 人間的であるかどうかを判断するモデルの構築
- 入力: エージェントの位置や
- 出力: 2クラス分類の結果(人間的であるかどうか)
- 使用ネットワーク: CNN・順伝播ネットワーク・GRU
分類モデルの入力
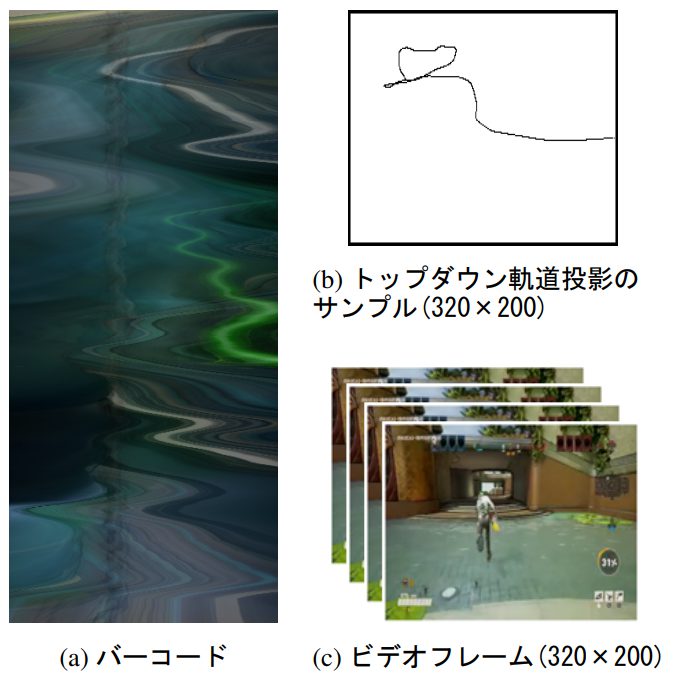
入力は様々な方法で表すことができます。図1に入力の例が示されています。
- シンボリック観測(SYM: Symbolic observations)
3D空間でのエージェントの位置 - ビジュアル観測(VIS: Visual observations)(c)
実際のゲーム映像(320×200)の画像 - トップダウン軌道投影(TD: Top-down trajectory projection)(b)
シンボリック観測の圧縮表現であり、エージェントの位置のz軸を抽出 - バーコード(BC: Bar-code)(a)
ビジュアル観測の圧縮表現であり、フレームのy次元に沿って平均

モデル構築のために、人間のプレイヤーとエージェントからプレイデータを収集する必要があります。Microsoftの研究者らが選んだゲームは、AAAという会社のものです。図2にはゲーム画面のスクリーンショットが示されています。
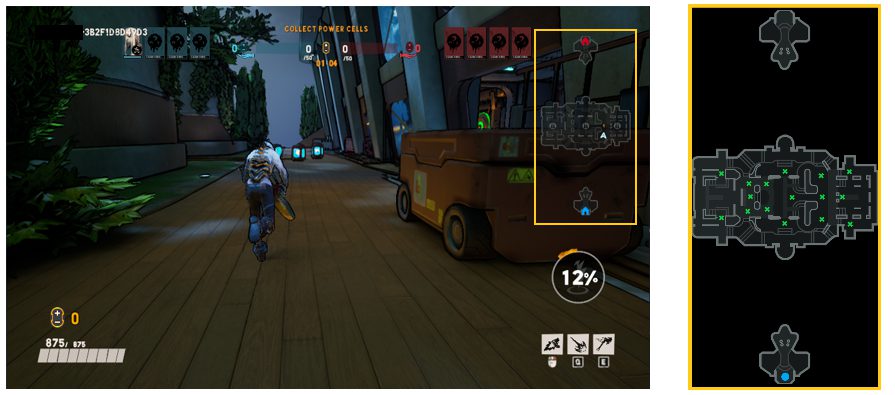
左側は人間が視認する画面で、右側がゲーム内のマップです。マップ内の青いアイコンはプレイヤーのスポーン位置を示し、緑の位置(16地点)はゴールの場所です。エージェントの学習においては、青い地点からいずれかの緑色の地点に行く方法を学ぶ必要があるでしょう。Microsoftの研究者らは予備テストを行いました。人間のプレイヤーはゴール位置にうまく誘導していることが分かりました。その際、平均所要時間は約26秒でした。
人間の操作データの収集
キャプチャソフトを使用し、合計7人のプレイヤーからデータが収集されました。ゲームの初級者から上級者まで、プレイヤーの熟練度は様々です。プレイ動画はMP4で保存され、分類器の訓練と検証のために100個、テストのために40個のデータに分割しました。
エージェントの操作データの収集
エージェントの学習には強化学習が用いられています。異なる2つのアーキテクチャによりエージェントが生成されました。図3(a)のアーキテクチャはシンボリックエージェントです。順伝播ネットワークを用いて処理され、ゴールとゲームの状態を考慮してエージェントの行動を決定します。
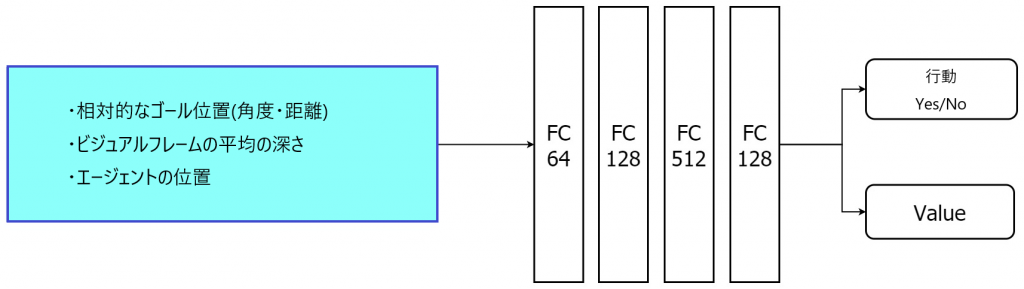
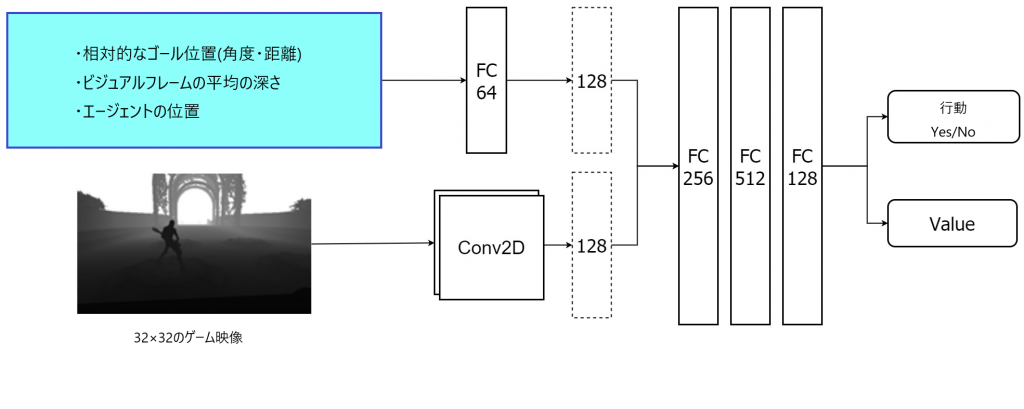
図3(b)のアーキテクチャはハイブリッドエージェントのものです。ハイブリッドは名前の通り、エージェントの位置やゴールの位置に加えて、ゲームの映像も入力として受け取ります。順伝播ネットワークを通す前に、CNNを通して特徴を抽出します。その後、エージェントの行動を決定します。
ゴールに到達すると+1の報酬、死んでしまうと-1のペナルティが課されます。さらに、キャラクターがステップを踏むごとに-0.01のペナルティが課されます。訓練はPPO(Proximal Policy Optimization)という強化学習手法を用いています。これは2017年にOpenAIが発表した手法です。
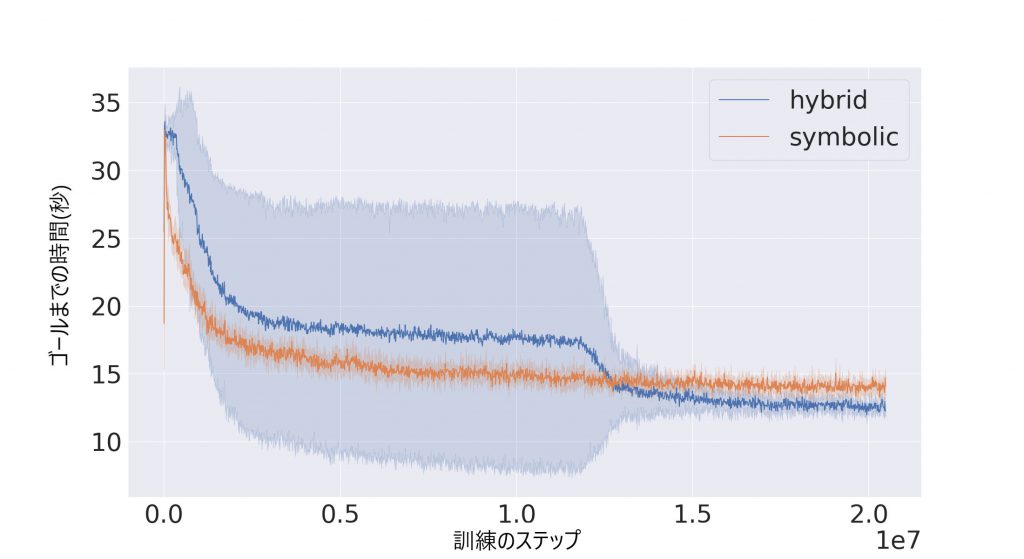
エージェントはゴールに向かうことを学習しました。図4に示すように、エージェントは正常に学習を終えています。青線がハイブリッドエージェントで黄色線がシンボリックエージェントです。最初の500万回で確実にゴールに行けるようになり、最終的には、ハイブリッドエージェントの方が10%タスクを早く完了していることが分かります。
モデルの詳細
分類のために用いられているネットワークについて、詳しく説明します。すべてのネットワークの概要は表1の通りです。

主に3つのネットワークが用いられています。
- 順伝搬ネットワーク(FF: Feedforward models)
最も単純なネットワークで、順に信号を伝える - ゲート付き回帰型ユニット(GRU: Gated Recurrent Unit)
RNNにおけるゲート構造で、LSTMと類似している - 畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)
画像入力に適用され、VGG-16が用いられている
モデルの訓練
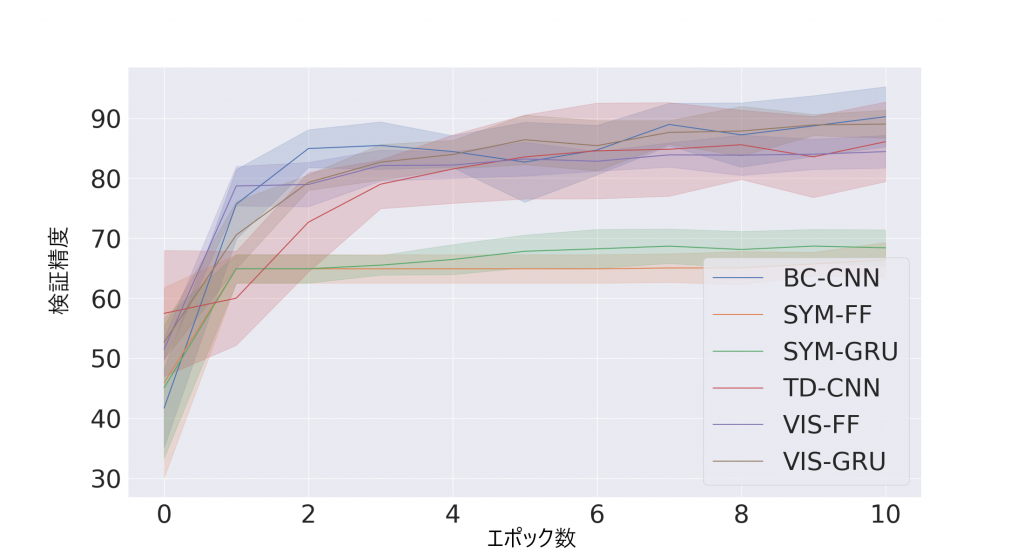
図5はANTTモデルのエポックに対する検証精度を表しています。シンボリックエージェントを用いて訓練されたモデルは、60-70%付近にあり精度が低いです。他のモデルは80-90%付近にあり、検証精度が高くなっています。
人間-エージェント間の判断タスクで分類器構築に成功
結果、人間とエージェントの人間的である方を判断するタスクにおいては、実用的な結果が得られ、分類器の精度は一番高いもので0.850となりました。
結果の検証では、まず正解データである人間の判断結果を収集する必要があります。これはゲームプレイヤーの動きが人間的であるかどうかを判断するチューリングテストです。次にMicrosoftの研究者らが作成したモデルを用いて、人間的であるかどうか二値分類を行います。その結果と正解データとを比較することにより、どれくらいモデルが正確であるかを比較しています。では、実際のデータ収集の方法を見ていきましょう。
正解データ(人間の判断)の収集
60人の人間がナビゲーションチューリングテスト(NTT)に参加しました。AとBのゲームプレイ動画があり、どちらがより「人間的」であるかを判定してもらっています。さらにその論理的根拠の記述が求められ、最後に自分の解答を「とても自信がある」から「あまり自信がない」までの5段階で評価することを求められます。図6はナビゲーションチューリングテストの回答画面です。
動画の1つはAIエージェントですが、他方の動画は人間もしくはエージェントです。つまり、エージェント2つを比較しどちらが人間的であるかを判定する場合も勿論あります。ここで用いられている2つのエージェントはハイブリッドエージェントとシンボリックエージェントです。

つまり、調査は2つのチューリングテストに分けられています。
調査1. 6回の試行で人間のプレイヤーとハイブリッドエージェントを判断し、4回の試行で2つのエージェントを比較する。
調査2. 6回の試行で人間のプレイヤーとシンボリックエージェントを判断し、4回の試行で2つのエージェントを比較する。
チューリングテスト(NTT)の評価
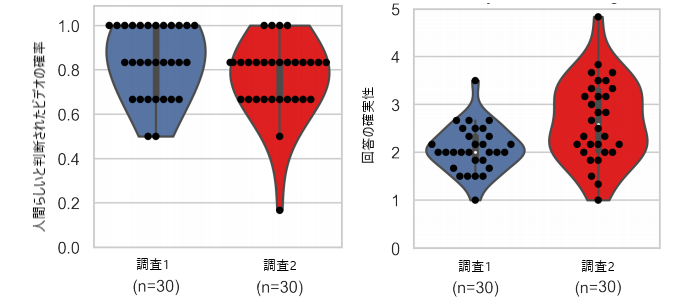
最初に、人間的であると正確に判定した確率をバイオリン図で示します。図7の左が確率のバイオリン図です。参加者はかなりの精度で人間のプレイヤーを正確に検出することができました。調査1の判定した確率の平均は0.84、調査2の平均は0.77でした。
次にMicrosoftの研究者らは、回答の不確実性を分析しました。1(とても自信がある)から5(あまり自信がない)の5段階です。調査2のほうがばらつきがあり、回答に自信がない参加者が増えています。
次に、参加者がシンボリックエージェントとハイブリットエージェントをどのように判断したかを調査ごとに比較しました。両方の調査において、直接エージェント同士を比較した場合、シンボリックエージェントよりもハイブリットエージェントの方がより人間的であると判断しました。
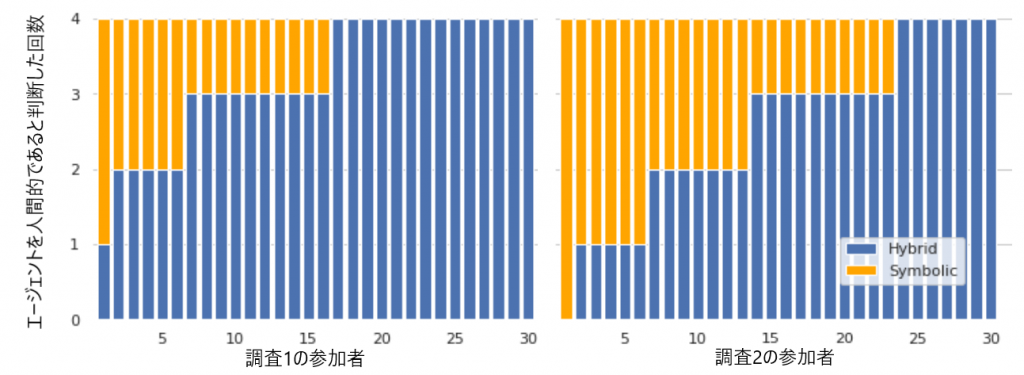
図8(左)では、調査1のエージェント同士の比較結果を表しています。結果はハイブリッドエージェントが人間的であると判断された確率はおよそ0.78でした。図8(右)では調査2のエージェント同士の比較を行っています。興味深いことに調査1の結果と比較して、調査2の方がシンボリックエージェントが人間的であると判断した人が多いです。ハイブリッドエージェントが人間的であると判断された確率はおよそ0.62でした。
結論としては、エージェント同士を直接比較した場合、ハイブリッドエージェントの方がより人間らしいと判断されることが分かりました。
分類モデル(ANTT)の評価
さらにMicrosoftの研究者らは、ANTTを用いて自動的にチューリングテストを行いました。表2は検討されたすべての分類器モデルの結果を示しています。注目してほしい結果は、人間とAgentを比較した精度と2種類のAgentを比較した精度です。つまりこの精度が表すのは、分類器がどれくらい人間の評価に沿うことができているかを表しています。
人間とエージェントを比較し、人間的である方を選ぶタスクでは、精度はかなり高くなっています。一番高いもので0.850もの確率を記録しています。しかしながら、二種類のエージェントを比較するタスクにおいては、精度はかなり低くなっていて、一番高いものでも0.525と実用的ではないように思えます。
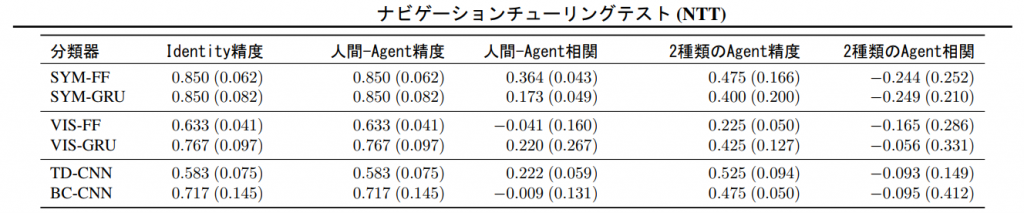
結論としては、人間とエージェントの人間的である方を判定するタスクにおいては、かなり良い結果が得られました。しかし、自動分類器をより実用的にするためには、両エージェントを判定するタスクにおける人間の判断と、分類器の判断のギャップを埋める必要があると考えます。
研究紹介は以上です。チューリングテストを自動化するという画期的な研究が行われました。人間的であるという要素を検出することは依然として未解決の問題のままですが、この研究によって、人間的なエージェントが作られるようになり、汎用型AIの実現に一歩踏み出せればよいと思います。
関連記事



■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。



























 PAGE TOP
PAGE TOP