
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

最終更新日:2022/12/05
こんにちは。エンジニアライターの小原です。
連載「現場にコミットする機械学習ノート」では、論文を詳しく読み解きながら、現場で使えるAI実装のヒントを記録していきたいと思います。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

前回の記事では、「AIでクラファンを成功させる秘訣を分析!」を扱いました。
今回は、中国のSchool of Management, Zhejiang UniversityのC. Zhangらが2020年9月(論文公開日)に発表した「機械学習で医療不正、薬物乱用を検知!」に関する論文を扱っていきます。
もくじ
1章 医療不正の課題
2章 AIで医療不正、薬物乱用を検出
2.1 研究目的:不正行為を検出したい
2.2 研究手法:NNとiForestを利用
2.3 研究結果: 不正検出にかかる時間を短縮させうる結果を示した
■前回の記事:【vol.34】 AIでクラファンを成功させる秘訣を分析!
1章
医療不正の課題
中国では、医療費の約1割が医療不正や乱用による無駄遣いで消費されているらしく、医療システムにとって重要な問題となっています。
しかし、医療分野では、数千種類もの薬剤や疾患が混在しており、データの数も膨大なので不正を防ぐために監視することは難しいです。
そこで中国のC. Zhangらは、アルゴリズムによって不正を検知することに挑戦しました。
このような技術は、日本でも薬局や保険組合での業務において活用できるのではないでしょうか?
2章
AIで医療不正、薬物乱用を検出
まずはC. Zhangらの研究におけるミッション・手法・結果をまとめます。
|
✔️ミッション ✔️解決手法 ✔️結果 |
研究の詳細を以下で述べます。
2.1 研究目的: 不正行為を検出したい
不正行為を発見するためには以下のようなハードルを越える必要があるます。
1. 正常データの数に比べて不正データの数はごくわずかであり、データの偏りが存在します。
2. 患者や医者それぞれで状況が様々であり、異常を明確に区別できる厳密なルールは存在せず、不正発見は難しいです。
3. 不正を行う者は不正を隠蔽するので、ルールベースでは不正検知しづらいです。
4. データは膨大なサイズであり、薬や疾病データが頻繁に変更されることもあるので、ロジックの更新には手間がかかります。
C. Zhangらは、ニューラルネットワークとを用いてこの課題をクリアしようと試みました。
2.2 研究手法:NNとiForestを利用
[データ]
中国浙江省杭州市からサンプリングされた30万人について2014年から取得され、暗号化された約737万件の治療記録を取得しました。
性能検証では、データベースからランダムにデータセットをサンプリングし、ラベル付けを行い100個の不正データと900個の正常データを作成して使用しました。
[前処理]
・データのサンプル数の偏りを調整するために、下図のようにダウンサンプリングとアップサンプリングを行いました。
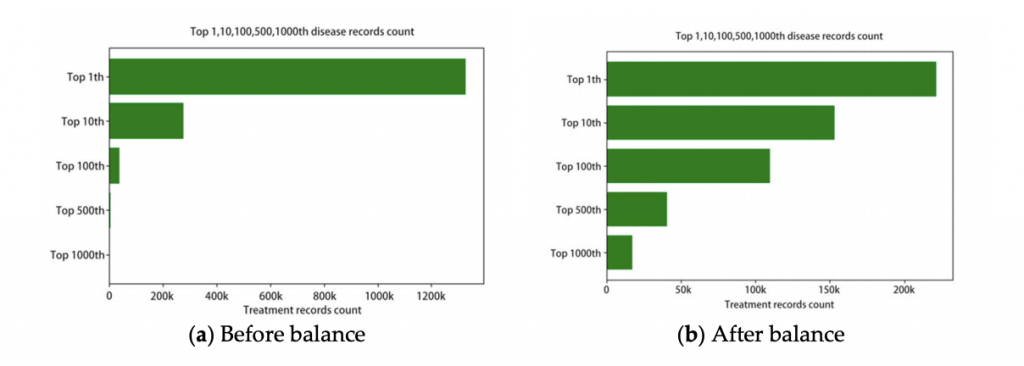

[特徴量]
複数の特徴量の不正行為や薬物乱用に関連する特徴量から共分散値や相互情報量を用いて重要ではない特徴を削除して以下を残しました。
・病気と処方薬品の関連スコア
・医療保険料率
・患者自身の負担率
・外来受診回数
・病院所在地
・患者のクレジットスコア
病気と処方薬品の関連スコアは以下のようにして求めました。
・取得したデータのうち、薬剤と疾患のカテゴリが頻度上位1000番のものだけを取り出しました。
・薬剤と疾患とをワンホットエンコーディングしました。
・下図左上のように7層で構成されるニューラルネットによって病気と処方薬品の関連スコアを特徴量として取得しました。
[特徴量抽出の流れ]
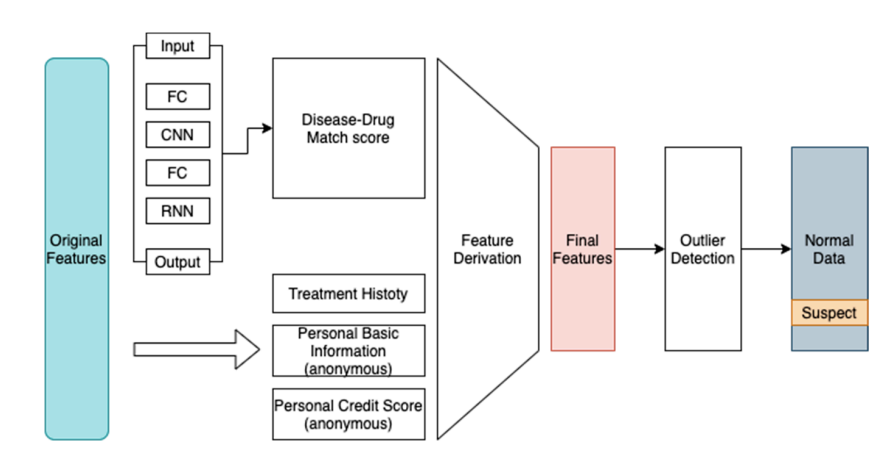
外れ値検出アルゴリズムにはアイソレーションフォレストを用いました。
・サンプルサイズ:256
・木の数:100
2.3 研究結果: 不正検出にかかる時間を短縮させうる結果を示した
結果、提案モデルは従来のモデルよりもはるかに優れた性能を有しており、分析者の作業を軽減することが可能であることが示唆されました。
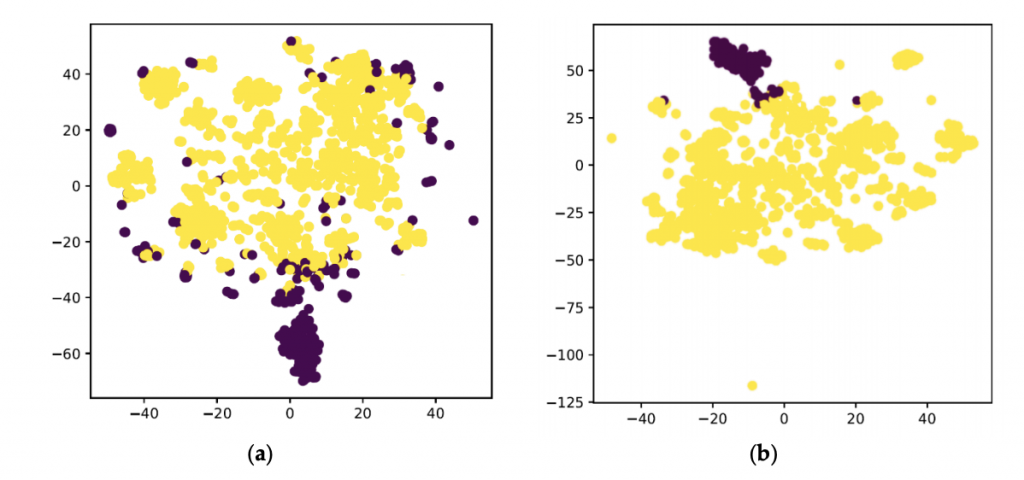
[可視化結果]
用いたデータセットでは、K-meansの精度がアイソレーションフォレストよりもはるかに低いことがわかりました。
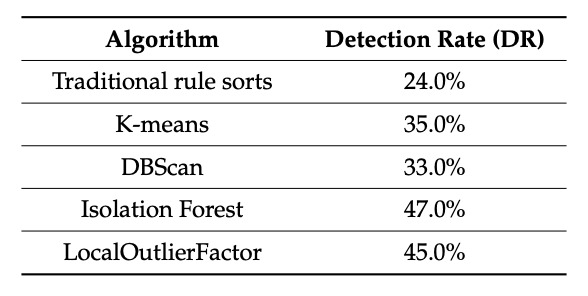
[アルゴリズムの性能比較]
アイソレーションフォレストは上位100件の中で47%の精度を得ることができ、最も精度の高い検出を行うことがわかりました。
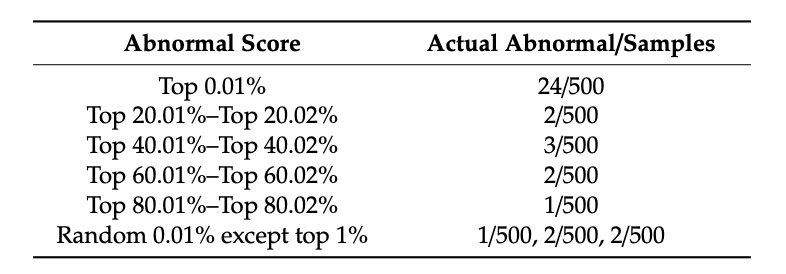
[提案手法で737万件の医療記録を対象に実験を行った結果]
(データ順の20%毎に500枚を連続サンプリングした後、手動でラベリングを行いました)
提案手法を用いることで不正が疑われる記録を集中的に検出することができ、手作業でのチェックの手間を省くことができます。
研究紹介は以上です。
このような技術を使えば莫大な医療費を削減できるかもしれないですね!
今回は「機械学習で医療不正、薬物乱用を検知!」について解説しました。
【現場にコミットする機械学習ノート・バックナンバー】

【vol.1】ウェハーの欠陥の分類
【vol.2】うつ病の分類
【vol.3】RNNによる農地作物の分類 #農業DXシリーズ
【vol.4】CNNによる土地の分類 #農業DXシリーズ
【vol.5】土地分類の一般化 #農業DXシリーズ
【vol.6】エッジデバイスで動く異常検知システム
【vol.7】エッジAIで異常を早期警告」
【vol.8】監視カメラ映像から危険物を検出
【vol.9】冬の画像を夏の画像に変換するAI技術
【vol.10】フルHDのアイトラッキング
【vol.11】可視光データで洪水状況を把握
【vol.12】衛星データとGoogle Earthエンジンで洪水を把握
【vol.13】音響を深層学習で船舶の種類を分類
【vol.14】キャベツ苗の欠陥を識別
すべてのバックナンバーはこちら
この記事で取り扱った論文:C. Zhang, X. Xiao and C. Wu,”Medical Fraud and Abuse Detection System Based on Machine Learning”,Int. J. Environ. Res. Public Health 2020, 17(19), 7265 DOI
※過去の全記事を閲覧されたい方はこちらからご登録よろしくお願いします!(会員登録は無料です。)

■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。



























 PAGE TOP
PAGE TOP