
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

最終更新日:2020/06/21
こんにちは。薬学部出身ライターのMasashiです。
連載「AI時代のくすり作り」では、新薬開発の現場でどのようにAIが活用されていくのかについて、論文を読み解きながら紹介していきます。
前回の記事では 「多くの病気を治す薬」を扱いました。第3回目は、「ビッグデータを活用した治療薬候補さがし」をテーマにお話ししていきます。
AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

前回の記事はこちら▶︎「多くの病気を治す薬」はこうして発見される
課題:効率的な創薬に重要な情報は見つけるのが難しい
薬は、特定の疾患に関連する標的遺伝子(またはタンパク質)に作用することにより、治療効果を発揮します。そのため、「遺伝子と疾患の関連情報」は、創薬にとって極めて重要となります。
これまで、遺伝学研究によって、数千種もの疾患関連遺伝子が同定されてきました。それらの疾患は、単一の遺伝子変異により生じるとされていましたが、実際には多くの疾患が複数の遺伝子によって引き起こされることが分かってきました。そのため、効率的な創薬を行うには、特定の疾患に関連する単一の遺伝子だけでなく、複数の遺伝子に有効な薬を見つける必要があります。

そんな課題に挑戦した、中国にある華中農業大学のYuan Quanらの研究を紹介します。
彼らは、複数の標的遺伝子に作用する有効な薬物の探索という課題に着目し、薬物活性予測モデルの開発を試みたのでした。
結果、薬物活性は予測できるようになったのでしょうか?
テーマ:複数遺伝子を標的とする化学物質の薬物活性を予測
まずはYuan Quanらの研究におけるミッション・手法・結果をまとめます。
|
✔️ミッション ✔️解決手法 ✔️結果 |
ミッションから紹介します。
目的:複数遺伝子に効く薬をみつける
遺伝学によって特定された疾患関連遺伝子は、薬物の有望な標的になり得ると考えられています。多くの疾患では、標的となる遺伝子が複数あるため、すべての遺伝子に活性を持つ化学物質を探し出すことは困難であるという課題があります。
そのため、活性の予測が今回の目的となりました。
手法:薬物活性予測モデルの構築
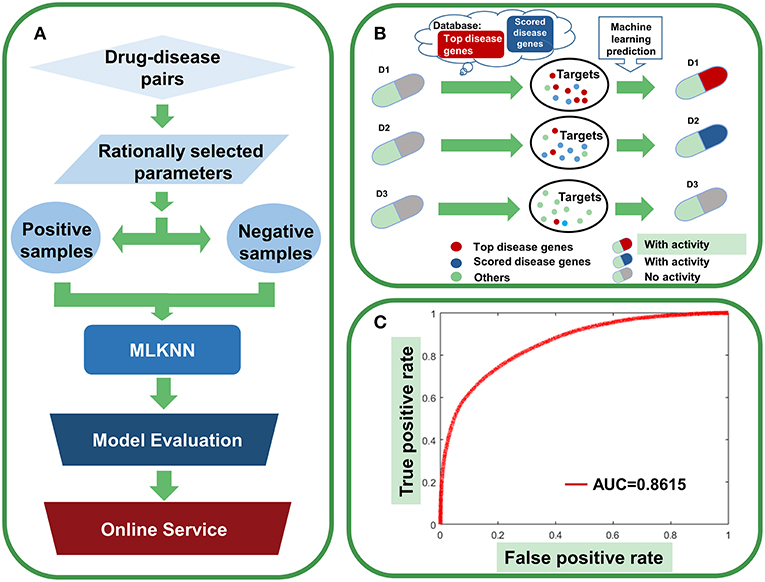
Yuan Quanらは、マルチラベルk近傍法(MLKNN)を用いて、薬物活性予測のための高精度マルチラベル予測モデルを構築しました。
具体的には、8つの疾患遺伝子データベースと3つの化合物データベースを用いて、薬物活性を予測しました。
結果:白血病に対する高い薬物活性を確認
結果、計11,649の活性を予測し、全体のパフォーマンスはAUCが0.8615でした。
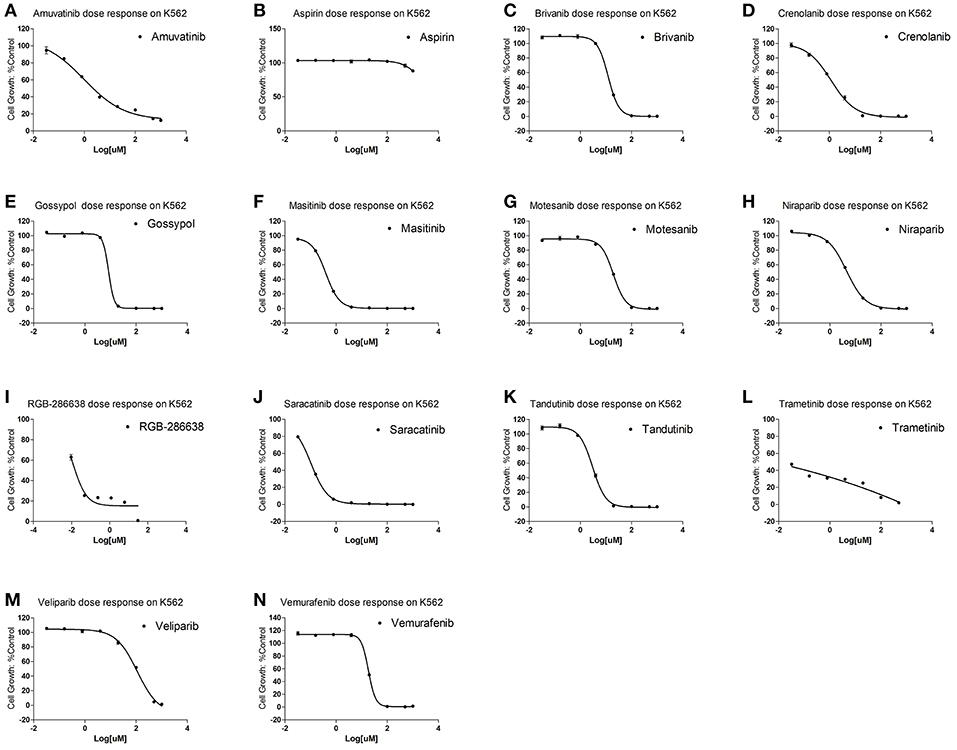
特に、白血病について最も良好な結果を示しました。809剤の薬物が白血病に有効である可能性が高いと予測され、そのうち550(67.99%)剤は、以前の臨床試験で検証されたものでした。
さらに、残りの259のうち14剤が市販されており、K562(慢性骨髄性白血病由来の癌細胞株)細胞毒性アッセイによって評価した結果、10剤(71.43%)がK562の増殖を効率的に阻害できることを示しました。
本研究により、複数の疾患遺伝子への作用に着目することが、高い活性を持つ薬物候補の発見に役立つことを明確に示し、遺伝学の進歩が創薬の発展に大きく寄与することが証明されました。
そしてそのように高度な「予測」タスクへのアプローチとして、ビッグデータを活用することが有効であると言えます。

研究紹介は以上です。遺伝学におけるビックデータの活用が、今後の創薬を大きく進歩させるでしょう。
第3回目は「多くの病気を治すかもしれない薬の開発」 をテーマにお話しいたしました。次回は、「鎮痛効果を持つ薬」の開発について取り上げていきます。お楽しみに!
【バックナンバーはこちら】

第一回 見限られた「抗菌薬開発」、機械学習で復活なるか
第二回 「多くの病気を治す薬」はこうして発見される
第三回 白血病の薬候補を探したビッグデータ活用手法とは?
第四回 鎮痛効果が期待できる薬の候補を発見
第五回 副作用の起こらない新薬候補を発見
この記事で取り扱った論文:Yuan Quan, et al.,”Systems Chemical Genetics-Based Drug Discovery: Prioritizing Agents Targeting Multiple/Reliable Disease-Associated Genes as Drug Candidates.”,Front. Genet., 10, 474 - DOI
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。



























 PAGE TOP
PAGE TOP