
★AIDB会員限定Discordを開設いたしました!
ログインの上、マイページをご覧ください。
★企業と人材のマッチングサービスを準備中です。アンケートのご協力をお願いいたします!↓

OCR研究の進捗は言語によってまちまち
書類の文章や動画中のテロップの文字を自動で認識する「光学式文字認識(OCR)」の技術は、英語や中国語など、幅広い言語で研究が進められている。
現在、ほとんどの言語には市販のOCRアプリケーションがあり、アプリを使って文字認識を行うことができる。しかし、一部の言語のOCR研究は進んでいないという現状がある。主にエチオピアで用いられている「アムハラ語」もその1つだ。
アムハラ語は多くの日本人にはなじみがないが、実はアラビア語に次ぐ世界で2番目に大きいセム語派である。アムハラ語を母国語として使っている人は5000万人以上、第二言語として使っている人は1億人以上であり、日本語話者に引けを取らない規模の大きさだ。
エチオピアの多くの歴史的文書および文学文書は、アムハラ語で記述されているが、アムハラ語の文字は子音によって形が変化する性質を持ため、機械による認識作業を難しくしている。

AIDBの全記事が読み放題のプレミアム会員登録はこちらから↓

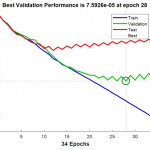
ドイツにあるカイザースラウテルン大学のB. Belayら研究者は、アムハラ語のOCRに関する研究が他の言語よりも進んでいないという課題に着目し、CNNとRNNを組み合わせた文字認識手法を試みた。
結果はどうだったのだろうか。すべての言語はデジタル化できるのか?
アムハラ語で書かれた文書のOCRに挑戦
B. Belayらの研究におけるミッション・手法・結果は以下の通りだ。

■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。


























 PAGE TOP
PAGE TOP